
一、问题诊断:你的替换为什么总像”硬贴上去的”?
1.1 一个让你感同身受的场景
想象这样一个创作需求:
你手上有一段极具氛围感的赛博朋克风格夜景街头视频——霓虹灯光在湿漉漉的柏油路面上拖出绚烂的倒影,镜头缓慢推进,烟雾在暗色调中弥漫。画面右侧有一块闪烁的日系霓虹招牌。
现在,你希望保持所有环境光影、镜头运动和氛围不变,仅仅把这块霓虹招牌替换成一盏中式古风红灯笼。
你在献丑AI选择视频编辑工具,输入:
把画面右侧的霓虹招牌换成一盏中式古风红灯笼
生成结果出来了。你的心凉了半截:
-
灯笼的红色与周围冷色调霓虹光完全割裂
-
灯笼表面没有任何湿漉漉的水汽反光
-
它看起来像是从一张春节贺卡上抠下来、硬贴到赛博朋克世界里的
这就是我们要解决的核心问题:为什么AI总是把元素替换做成了”拼贴画”?
1.2 底层原因拆解:AI的三重认知盲区
要彻底解决问题,必须先理解AI”犯错”的底层机制。替换失败并非AI”笨”,而是当前模型架构在处理局部替换时存在三个结构性盲区:
盲区一:文本编码器(Text Encoder)的”联想偏差”
当你输入”中式古风红灯笼”时,AI的文本编码器会将这段文字转化为一组高维向量。问题在于,这组向量代表的是AI训练数据中”灯笼”这个概念的统计平均值——那些数据绝大多数是明亮场景下、暖色调的节庆灯笼照片。
AI脑中浮现的”灯笼”,是阳光下的大红灯笼,而不是”被赛博朋克霓虹灯浸染、表面带有雨水反光的质感灯笼”。文字描述无法精确传达”这个特定环境下灯笼应有的视觉状态”。
盲区二:视频重绘的算力瓶颈
视频重绘(Video Repaint)本质上是一个条件生成(Conditional Generation)过程。模型需要在有限的去噪步数内,同时完成两件互相矛盾的事:
-
保持未遮罩区域的像素不变(保留背景)
-
在遮罩区域内生成与周围环境光影完全一致的新内容(替换元素)
当替换前后的元素存在巨大的”视觉风格跨度”(例如从霓虹招牌到古风灯笼),模型需要在极有限的计算预算内完成一次”跨次元风格翻译”——这几乎是不可能的任务。
盲区三:缺乏”空间锚点”的方向迷失
纯文本指令只告诉AI”放什么”,却没有告诉它”放在哪里、多大、什么角度、什么光照条件”。没有视觉参考的替换,本质上是让AI在黑暗中射箭。
💡 关键结论:提示词是”方向盘”,但视觉参考图才是”导航地图”。没有地图光靠方向盘,你永远到不了目的地。
1.3 一张表看清差距
| 维度 | 纯文本替换 ❌ | 视觉锚定替换 ✅ |
|---|---|---|
| 风格匹配 | AI按训练数据的”平均印象”生成 | AI以参考图为”标准答案”对齐 |
| 光影一致性 | 新元素自带”出厂默认光照” | 新元素继承原画面的光影环境 |
| 材质融合度 | 平面化、卡通化、与环境割裂 | 表面质感与周围环境自然过渡 |
| 空间定位 | 大小/位置/角度靠AI猜测 | 大小/位置/角度有明确参照 |
| 成功率 | 约10%-20%,严重依赖运气 | 约70%-90%,可控可复现 |
理解了”为什么会失败”,我们就可以对症下药了。
二、第一层心法:单图锚定法——给AI一张”标准答案”
2.1 核心思想
先在静态图层面完成”风格翻译”,获得一张已经与原画面光影融合的替换元素图,再将这张图作为视觉锚点注入视频重绘流程。
简单说就是:别让AI在视频里直接”现场发挥”,先在图片上把”正确答案”做出来,再让AI对着答案抄。
2.2 完整操作流程
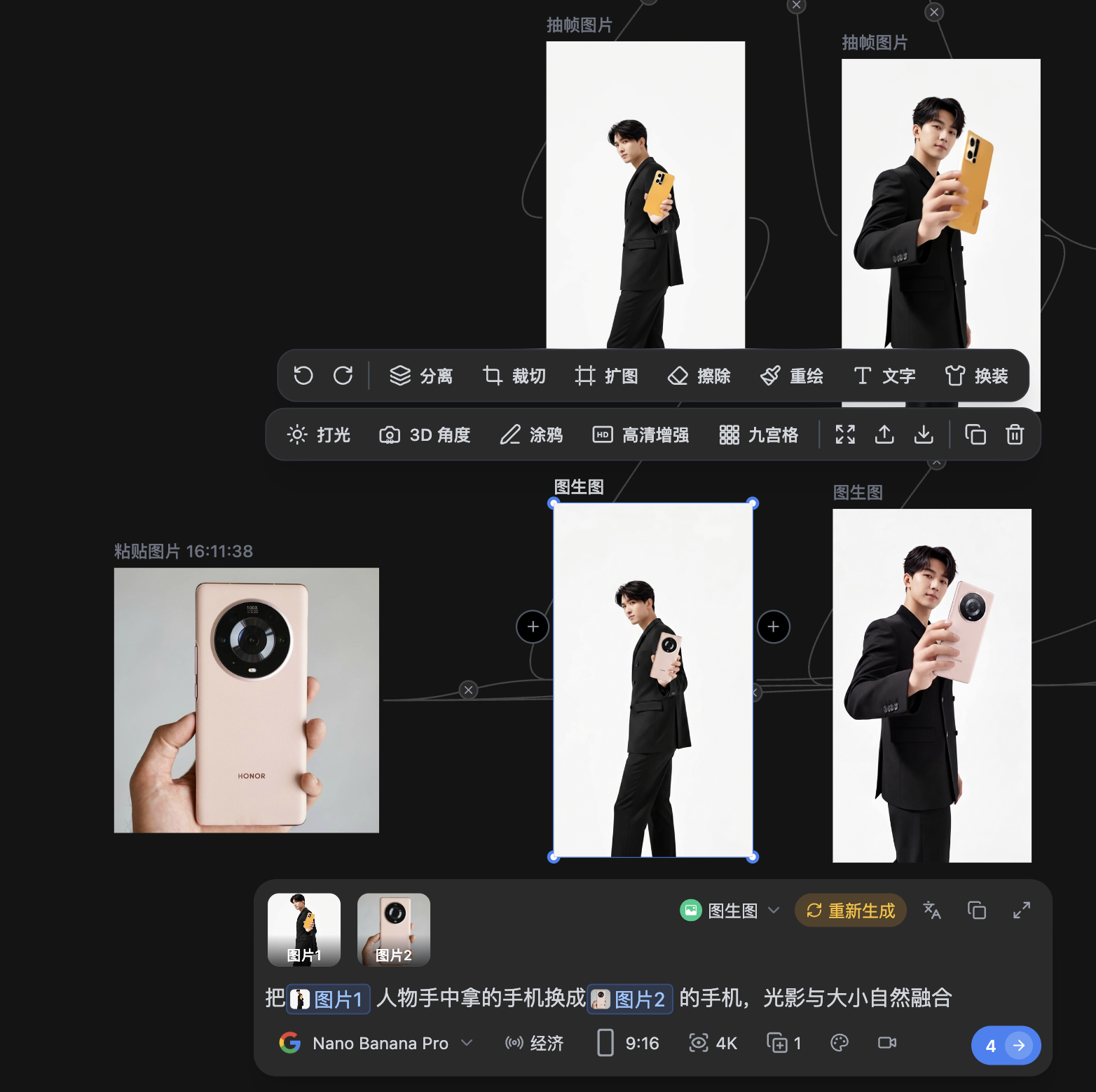
场景设定:你有一段咖啡店Vlog视频,镜头缓慢平移扫过吧台。吧台上有一只白色纸杯,你希望将它替换为你自己品牌的深棕色陶瓷杯——杯身印有手绘风格的logo。
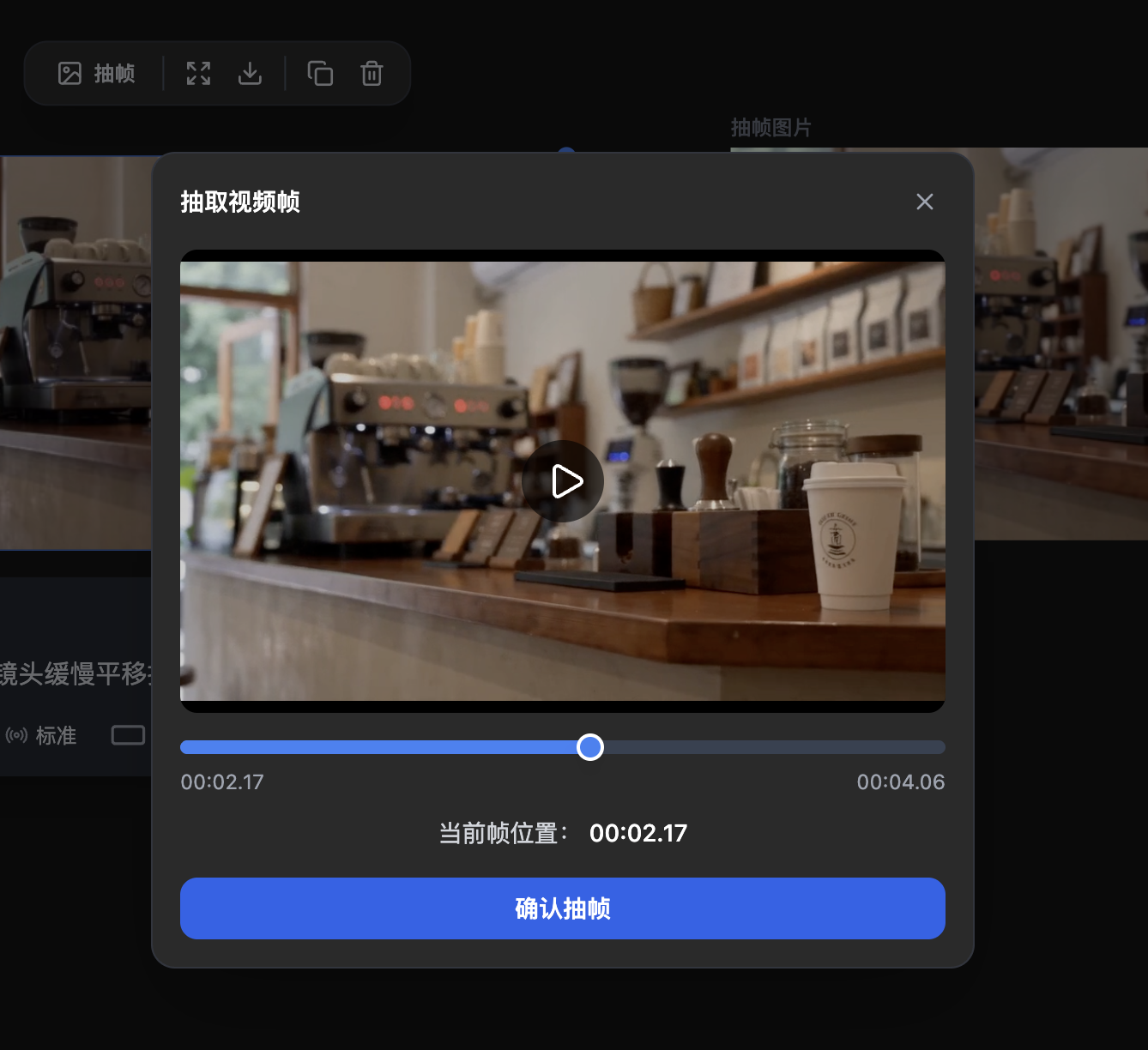
Step 1:截取视频首关键帧作为操作底图
从原始视频中导出第一帧画面(献丑AI有提取帧的功能可以直接使用)。 但是这个杯子在最后一帧,那么我们这个杯子完整出现的这一帧
⚠️ 注意:选择的帧应该是目标元素(纸杯)最清晰、最完整呈现的那一帧,避免运动模糊帧。
Step 2:在 献丑AI 中完成静态图替换
将首帧图导入 献丑AI 的局部重绘功能,或者你直接用提示词替换,因为这个杯子比较好描述清晰。
普通写法 vs 专业写法对比:
❌ 普通写法: 把纸杯换成棕色陶瓷杯 ✅ 专业写法: 将画面中的白色纸杯替换为深棕色哑光陶瓷杯,杯身有手绘风格的暖色调logo。 保持与原画面完全一致的自然光照方向(从左上方窗户射入), 杯体表面呈现与周围木质吧台相协调的暖色反光,杯口边缘有轻微的高光。
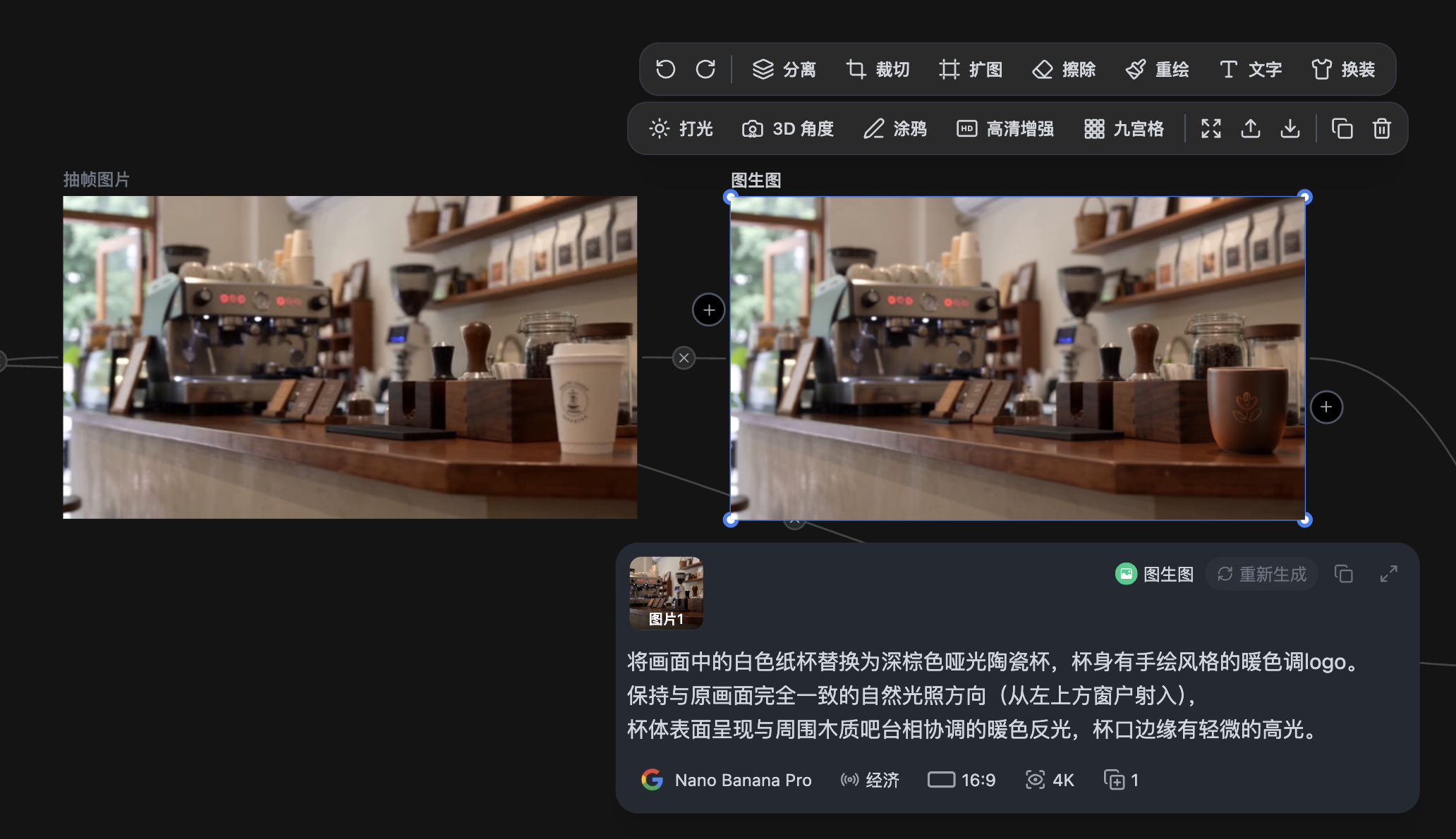
为什么专业写法有效?因为你主动为AI补全了它的三大盲区:
-
明确了材质(哑光陶瓷)→ 解决联想偏差
-
描述了光照方向(左上方窗户光)→ 解决光影割裂
-
指定了反光特征(木质吧台反光)→ 解决环境融合
💡 Tips:Nano Banana Pro 基于强大的多模态理解能力,能”看懂”原图的场景语义——光照方向、透视关系、3D空间逻辑——然后在遮罩区域内生成与上下文高度一致的新内容。这是它区别于传统修图工具的核心优势。
Step 3:将修改后的静态图 + 原视频一起输入可灵 3.0 Omni
打开可灵AI 3.0 Omni模型,上传原始视频和刚才在Nano Banana Pro中生成的替换图。
参考上传的图片,将视频中吧台上的白色纸杯替换为图片中的深棕色陶瓷杯, 保持视频其余所有元素不变
点击生成。
2.3 原理透视:为什么”先图后视频”比”直接改视频”有效?
这背后涉及扩散模型的条件注入机制。
在视频重绘的去噪过程中,模型需要在每一步迭代中同时参考多个条件信号:文本提示、原始视频帧、以及参考图像。当你提供了一张已经完成了”风格翻译”的静态参考图时:
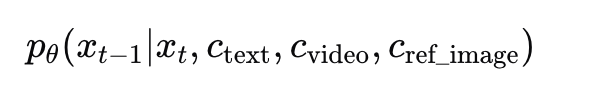
其中 cref_image 作为一个极强的视觉先验,大幅压缩了模型在遮罩区域内的”搜索空间”。AI不再需要从零猜测”替换物长什么样”,而是直接以参考图为蓝本,在视频的运动轨迹中”复刻”它。
打个比方:让一个画家凭描述画一只”带有电影质感光影的陶瓷杯”,和直接给他一张照片让他临摹——后者的成功率和效率是碾压性的。
2.4 适用边界与局限
单图锚定法并非万能。它有明确的最佳适用条件:
| 条件 | 适合 ✅ | 不适合 ❌ |
|---|---|---|
| 元素运动幅度 | 小幅度(微微晃动、静态摆放) | 大幅度(旋转、翻转、快速位移) |
| 可见角度变化 | 基本不变或轻微变化 | 从正面转到侧面、背面 |
| 遮挡关系 | 简单(无遮挡或固定遮挡) | 复杂(被其他物体交替遮挡) |
| 光影变化 | 稳定光源 | 剧烈明暗交替(如穿过树荫) |
当元素在视频中存在大角度旋转或复杂运动时,单张参考图无法覆盖所有视角,AI在中间帧将失去参照而”崩坏”。 这时,你需要升级到第二层心法。
三、第二层心法:多帧序列锚定法——用关键帧”画出运动轨迹”
3.1 什么场景必须升级?
当你的替换目标在视频中存在以下任一情况时,单图锚定必然失效:
-
🔄 大角度旋转:物体从正面转到侧面或背面
-
💡 光影剧变:受光面和背光面在运动中持续切换
-
🫣 遮挡变化:物体被其他元素交替遮挡和露出
-
📐 透视形变:近大远小的透视关系在运动中持续变化
核心逻辑:一张参考图只能锁定一个视角。当视频中目标元素经历了多个截然不同的视角时,你需要为每个关键视角都提供一张”标准答案”——形成一条视觉锚点序列,像路标一样指引AI完成整段视频的重绘。
3.2 完整操作流程
场景设定:你有一段手持旋转展示手机的产品视频——从正面展示屏幕,缓慢旋转到侧面展示厚度,再转到背面展示摄像头模组。你需要将视频中的旧款手机替换为一款全新的概念机型。
Step 1:按”运动拐点”提取关键帧
观察视频中手机的运动轨迹,可以在以下节点截取关键帧:
| 关键帧编号 | 时间点 | 视角描述 |
|---|---|---|
| 帧① | 0:00 | 正面朝向镜头,手机背面完整可见 |
| 帧② | 0:02 | 旋转至约45度,屏幕和侧面各占一半 |
| 帧③ | 0:04 | 完全侧面,展示机身厚度 |
| 帧④ | 0:06 | 旋转至背面,摄像头模组完整可见 |
💡 关键帧选取的黄金法则:
运动拐点——物体改变运动方向的瞬间
光影突变点——受光面发生显著切换的瞬间
遮挡分界点——物体从被遮挡到露出(或反之)的瞬间
通常4-6帧即可。过少会让AI在两帧之间”脑补”出错,过多则增加工作量且可能引入帧间不一致。
Step 2:在 Nano Banana Pro 中逐帧完成替换
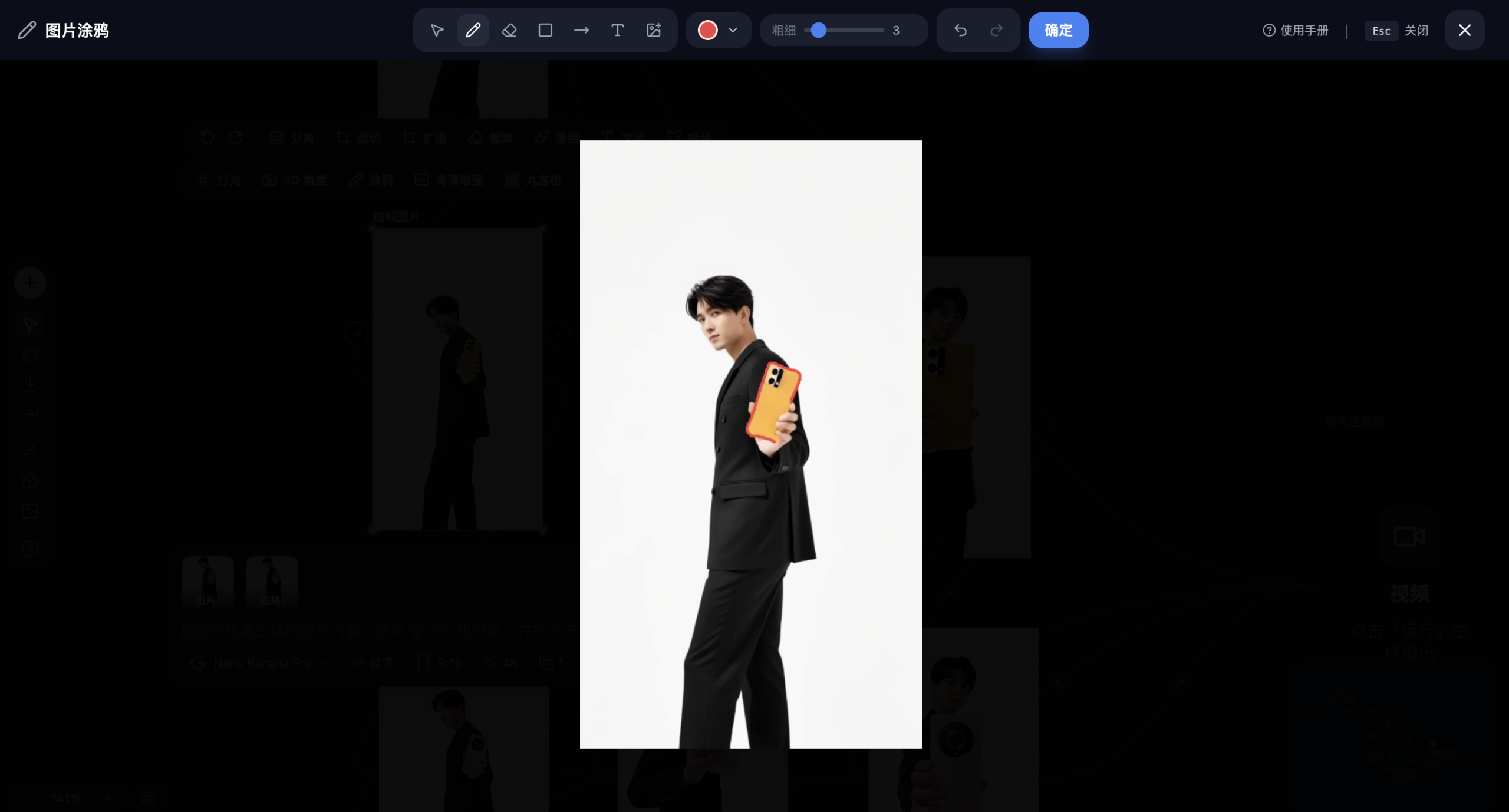
你可以像上图一样给手机绘制出框线以便于改图的时候更加融合,将每张带框线的关键帧与新手机的参考图一起输入Nano Banana Pro,进行逐帧重绘。
以帧②(45度视角)为例的专业提示词:
将图中红色框线区域内的手机替换为参考图中的新款概念手机。 当前视角为约45度侧视,需呈现屏幕的侧面透视缩短效果和机身侧面的金属质感。 保持与原画面一致的室内柔光照明。 替换元素的大小和位置应与原手机完全匹配。 或者你也可以写 把@图片1 人物手中拿的手机换成@图片2 的手机,光影与大小自然融合
逐帧重绘时保持风格一致性的关键:
-
每一帧的提示词中都需要重复相同的材质描述和光照描述
-
使用相同的参考图(新手机的标准产品照)
-
如果工具支持,锁定相同的随机种子(Seed)以减少帧间风格波动
Step 4:将序列帧按顺序输入可灵 3.0 Omni
打开可灵AI 3.0 Omni模型,上传原始视频 + 按时间顺序排列的4张替换后关键帧。
参考上传的视频,将视频中手持展示的手机替换为图片中的新款手机。 请严格按照图片1→图片2→图片3→图片4的时间顺序, 对应视频从正面→45度→侧面→背面的旋转过程进行替换。 保持视频中手的动作、背景环境及整体光影完全不变。
点击生成。
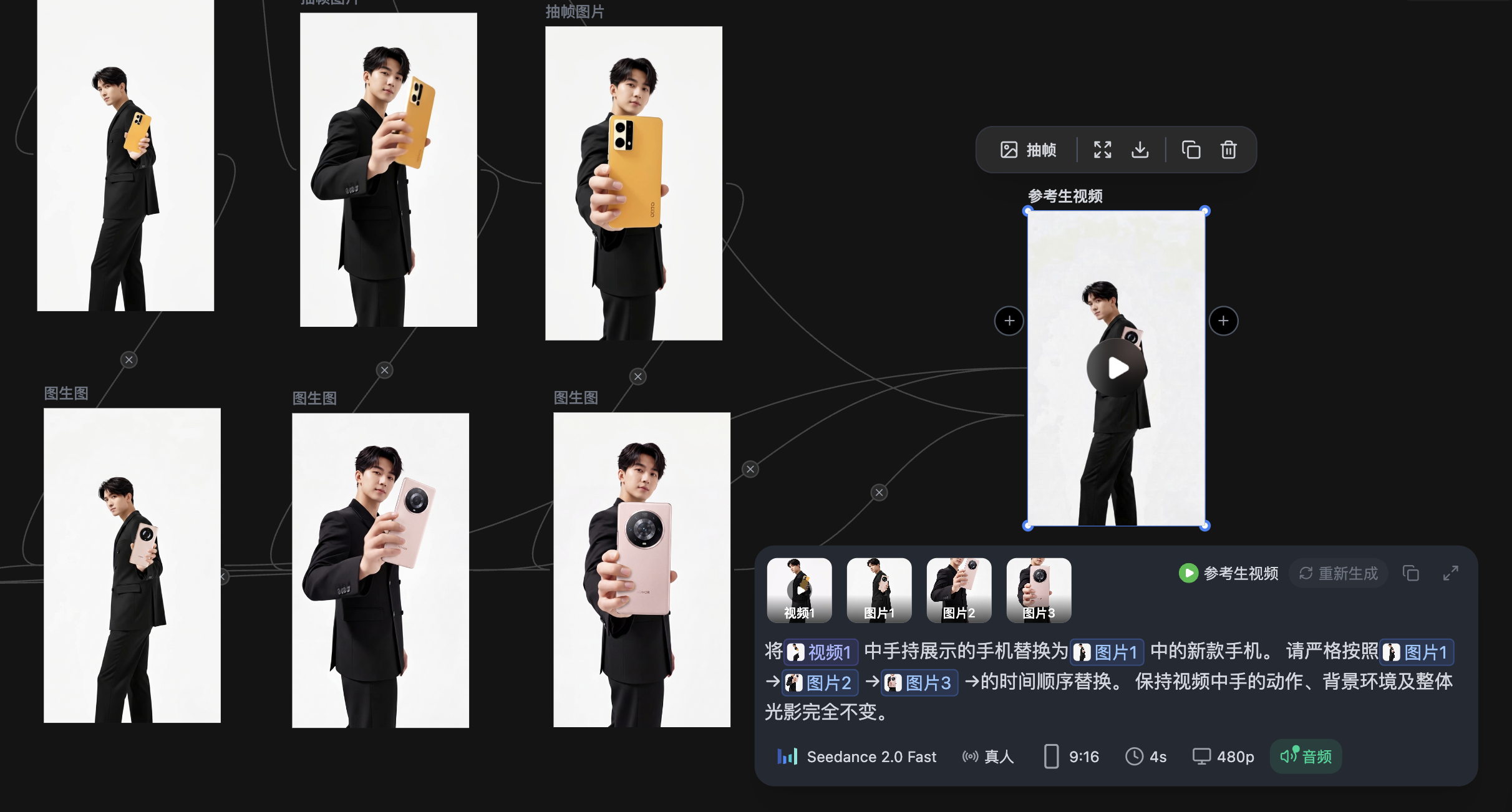
这里最后有些不同,我用的是seedance2.0模型,比较丝滑但是没有可灵这么参考我的图片,我没有再增加抽卡,但是要特别精准可以再加一帧去控制或者用可灵3.0,但是目前效果出来让大家了解了就行
3.3 原理透视:”多图锚定”为何能驯服大幅度运动?
可灵 3.0 Omni 的元素参考(Element Reference)机制和多图输入能力是这套方法的技术基础。
根据可灵官方的技术文档,3.0 Omni 模型在处理多张参考图时,会将它们视为同一物体在不同时间点的视觉约束条件。模型内部的时序注意力机制(Temporal Attention)会在相邻关键帧之间建立”插值走廊”——对两个锚点之间的中间帧,模型会基于运动趋势进行受控插值,而不是无锚点的自由发挥。
用一个直观的类比:
-
单图锚定 = 给AI一个目的地坐标,让它自己选路。路上遇到岔路(角度变化),AI可能会跑偏。
-
多帧锚定 = 在每个岔路口都放一个路标。AI在路标之间只需走最短的直线,大幅降低了跑偏的概率。
3.4 提示词工程:融合一致性模板
在逐帧操作Nano Banana Pro时,使用以下统一模板结构可以显著提升帧间一致性:
[替换指令] 将遮罩区域内的{旧元素}替换为参考图中的{新元素}。 [视角声明] 当前视角为{具体角度描述}。 [材质锚定] 新元素表面应呈现{材质描述},与原画面中{周围物体}的质感保持协调。 [光照锚定] 保持与原画面完全一致的{光源方向和类型}, {特定部位}应呈现与{环境元素}相协调的{反光/阴影类型}。 [尺寸锚定] 替换元素的大小和空间位置应与原始元素完全匹配。
⚠️ 常见踩坑提醒:
关键帧数量不是越多越好。4-6帧通常是效率和质量的最优平衡点。帧数过多时,各帧之间的微小风格差异反而可能让AI产生”选择困难”,导致中间帧出现闪烁。
不要跳过”遮罩绘制”步骤。虽然有些工具支持自动识别目标元素,但手动遮罩能给你更精确的边界控制,尤其是处理半透明、毛发、烟雾等复杂边缘时。
四、第三层心法:认知升维——理解AI的”算力局限”才是最高段位
4.1 重新定义”精准替换”
学完前两层方法后,很多创作者会陷入一个误区:追求用更复杂的提示词、更多的参考图来”堆料”。
但真正的高手知道:精准替换比拼的不是技术操作的复杂度,而是你对AI能力边界的判断力。
核心认知转变:
你不是在”指挥AI做替换”,而是在”判断AI在哪些环节需要人类辅助”。
AI擅长的是:在给定明确视觉参考和空间约束的情况下,高效地完成像素级别的融合渲染。
AI不擅长的是:跨风格的”想象力翻译”、多视角的”3D一致性推理”、以及长序列的”时序连贯性维持”。
你的工作,是把AI不擅长的部分预先解决掉,只让AI做它最擅长的事。
4.2 决策框架:根据场景特征选方法
面对一个具体的替换需求时,用这张速查表在5秒内判断应该使用哪一层方法:
| 同风格替换(如红杯→蓝杯) | 跨风格替换(如纸杯→陶瓷杯) | 跨次元替换(如卡通→写实) | |
|---|---|---|---|
| 低运动幅度(近似静止) | ✅ 直接文本替换即可 | ✅ 第一层:单图锚定 | ✅ 第一层:单图锚定 |
| 中运动幅度(平移、小幅摇摆) | ✅ 第一层:单图锚定 | ✅ 第一层:单图锚定 | 🔶 第一层或第二层,视情况而定 |
| 高运动幅度(旋转、翻转、大位移) | 🔶 第一层或第二层 | 🔶 第二层:多帧序列锚定 | 🔴 第二层:多帧序列锚定(必须) |
4.3 工具选型指南
2026年主流的两大视频重绘工具各有所长:
| 对比维度 | 可灵(Kling)3.0 Omni | 即梦AI Seedance 2.0 |
|---|---|---|
| 开发团队 | 快手(Kuaishou) | 字节跳动(ByteDance) |
| 核心优势 | 元素参考(Element)系统精准,@标签语法灵活 | 多模态混合输入(最多12个素材),原生音视频同步 |
| 参考图执行度 | ⭐⭐⭐⭐⭐ 极高,几乎”照抄”参考 | ⭐⭐⭐⭐ 高,但会加入更多”创意发挥” |
| 多镜头控制 | 支持,每镜头可独立设置提示词和时长 | 支持,原生多镜头叙事能力,自动分镜 |
| 最大时长 | 单次生成 ≤ 15秒 | 单次生成 ≤ 15秒 |
| 最佳适用场景 | 需要严格保持参考图外观的精准替换 | 需要音画同步或多素材混合驱动的创意替换 |
💡 实用建议:如果你的需求是”替换后的元素必须和参考图一模一样”(如品牌产品植入),优先选可灵 3.0 Omni。如果你的需求是”替换后的整体氛围和节奏感要好”(如创意短视频),即梦 Seedance 2.0 可能给你更多惊喜。
###
五、总结与行动清单
核心要点回顾
三层方法的递进逻辑:
第一层:单图锚定 → 解决"AI不知道替换物长什么样" ↓ 运动幅度增大时升级 第二层:多帧序列锚定 → 解决"AI不知道替换物在不同角度长什么样" ↓ 认知层面的升维 第三层:决策框架 → 解决"我应该在什么场景用什么方法"
一句话总结:
高手与新手的分水岭,不在于谁的提示词写得更华丽,而在于谁更懂得——在AI”看不见”的地方,提前铺好视觉路标。
🎯 可立即执行的5步行动清单
-
下次替换前,先问自己一个问题:”这个元素在视频中的运动幅度有多大?”——用这个答案决定使用第一层还是第二层方法。
-
养成”先做静态图验证”的习惯:永远不要直接在视频中尝试替换。先在Nano Banana Pro上用一张静态帧验证替换效果,确认光影和材质没问题后,再进入视频流程。
-
学会截取关键帧:去掌握你常用的视频播放器(如PotPlayer、VLC)的逐帧快进功能(通常是快捷键
.和,),这是多帧锚定法的基本功。 -
提示词中永远包含”光影描述”和”材质描述”:不要只写”换成XX”,至少补充光源方向、表面材质、环境反光这三个要素。
-
建立你自己的”工具-场景匹配表”:用本文的决策框架做10次真实测试,记录每个工具在不同场景下的表现,形成你个人的最佳实践手册。
掌握了”视觉锚定”的思维方式后,你会发现:AI不是不听话,只是需要更聪明的指引方式。下一次当替换结果让你皱眉时,不要死磕提示词——退回一步,先做一张”标准答案”给它看。
发表回复