
当你试图用AI视频展示一款精美的产品时,放大画面却发现Logo在游走、瓶身在融化、材质光泽逐帧跳变——这不是你的模型”不行”,而是你给AI的控制信号密度不够。本文将从扩散模型的概率预测本质出发,带你理解形变的根因,并提供两套分级解决方案(商业级逐帧锁定 + 效率级黄金单帧),工具链基于 Nano Banana Pro + 献丑AI / 可灵AI 3.0 / 即梦Seedance 2.0,即学即用。
一、诊断:AI视频产品形变的底层病因
1.1 扩散模型(Diffusion Model)的”猜测”本质
要理解为什么AI视频中的产品会”变形”,我们必须先搞清楚一件事——AI从来不”知道”你的产品长什么样。
当前主流视频生成模型(可灵3.0、即梦Seedance等)的底层架构均基于扩散模型。其工作原理可以简化为:
-
正向过程:将真实视频逐步加入随机噪声,直到完全变为纯噪声
-
反向过程:从纯噪声出发,根据条件信号(提示词/参考图)逐步”去噪”,预测出每一帧的像素

关键认知:这个”逐步去噪”的过程,本质上是一个概率采样过程。模型在每个去噪步骤中,不是”复制”你的产品,而是在一个巨大的概率分布中”采样”——它根据你给出的条件信号,选择一个”最可能”的像素排列组合。
💡 类比理解:想象你口述一个杯子的样子,让100位画家各画一幅——每个人画出来的都”合理”,但没有两幅完全相同。AI的每一帧,就相当于一位新画家的独立创作。
1.2 信息密度稀释效应
为什么静态的AI图片能保持一致,而视频就会”跑偏”?
答案在于信息密度的时间维度稀释:
| 控制方式 | 信息密度 | 覆盖范围 | 形变风险 |
|---|---|---|---|
| 仅文字提示词 | ⭐ 极低 | 全时间轴一次性注入 | 🔴 极高 |
| 单帧参考图(首帧) | ⭐⭐ 低 | 仅第一帧确定,后续衰减 | 🔴 高 |
| 多帧关键帧参考 | ⭐⭐⭐⭐ 高 | 多个时间节点锁定 | 🟢 低 |
| 逐帧精确参考 | ⭐⭐⭐⭐⭐ 极高 | 全时间轴覆盖 | 🟢 极低 |
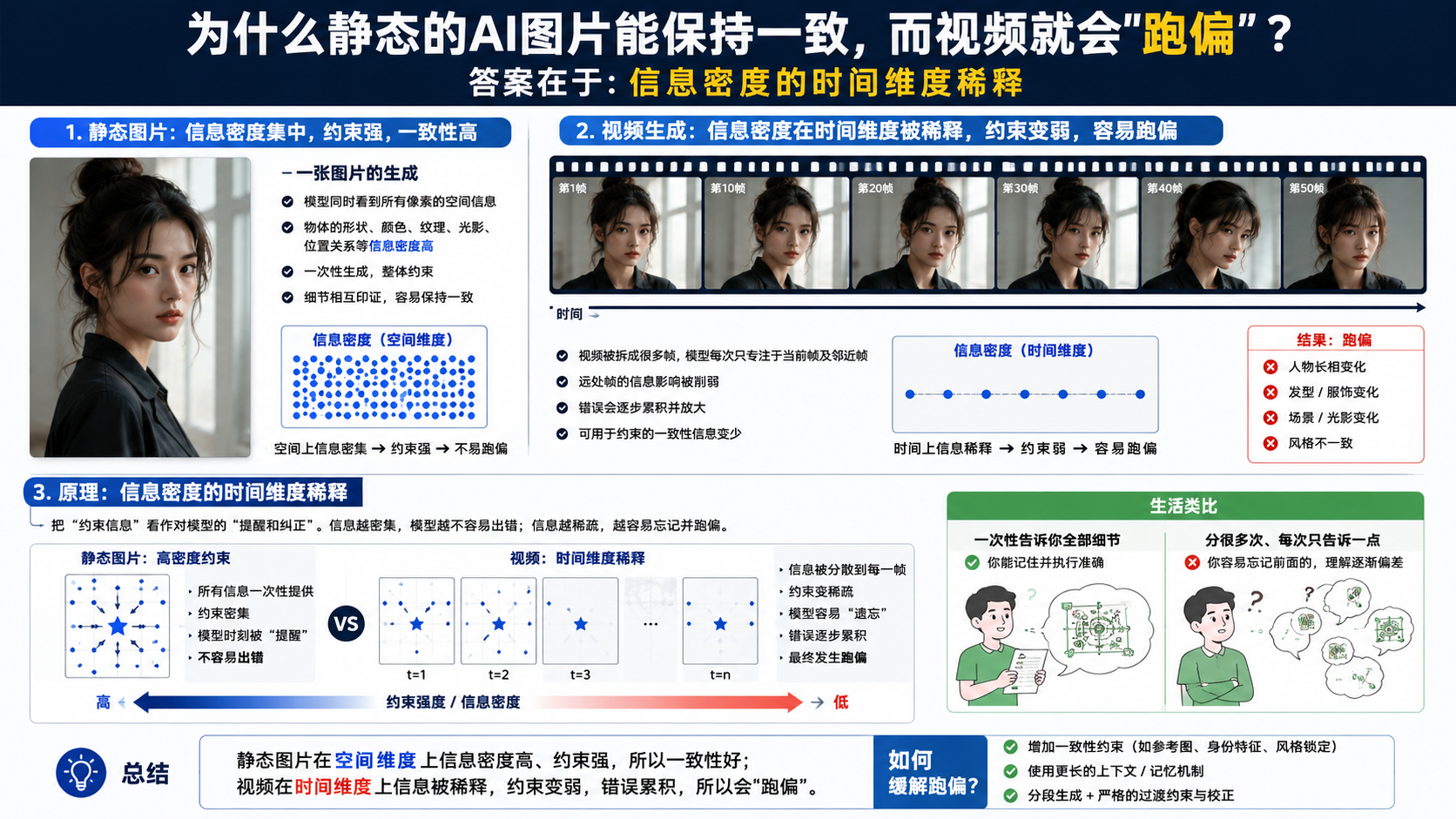
当你只给一张首帧参考图时,模型在第1帧有非常强的”约束力”。但随着时间推移到第30帧、第60帧,这个约束力会被每一步采样的随机性不断”侵蚀”——就像一个清晰的无线电信号,在传输过程中被噪声逐渐淹没。
1.3 用”信噪比”思维理解形变
我们可以将这个问题抽象为一个公式:

-
控制信号强度取决于:参考图的数量、精度、在时间轴上的覆盖密度
-
采样噪声取决于:运动幅度、光影变化复杂度、镜头转换剧烈程度
核心结论:要解决一致性问题,本质上就是在时间轴的关键节点反复注入高确定性的参考信息,将模型的”自由发挥空间”压缩到最小,而上述公式如果得出的值越大,得到的画面一致性越好。
二、工具链:精准重绘引擎 × 时间连贯性引擎
解决这个问题需要两类工具的精密配合:一个负责”定义每一帧的标准答案”,另一个负责”让标准答案之间平滑过渡”。
2.1 Nano Banana Pro——像素级改写利器
核心能力一览:
| 能力维度 | 具体表现 |
|---|---|
| 多图融合 | 最多接受 14张参考图,保持最多5个人物的一致性 |
| 局部编辑 | 精确选择、替换、变换图像中的任意局部区域 |
| 主体保留 | 上传产品图后,能将其精准融入任意场景,保持纹理/Logo/材质不变 |
| 输出质量 | 支持 2K/4K 分辨率原生输出 |
| 世界知识 | 可实时调用 Google Search 知识库,确保生成内容的准确性 |
接入方式:
-
Google Flow 平台(需 Google AI Ultra 订阅)
-
Gemini App(选择”Thinking”模型创建图像)
-
Google AI Studio / Vertex AI(开发者API)
-
不过这里推荐一个好的国外集成平台get3w(get3w.com)
⚠️ 注意:访问 Google Flow 需要网络代理工具。Nano Banana Pro 与此前的 Nano Banana 2(基于 Gemini 3.1 Flash)的核心区别在于——Pro版本拥有更强的推理能力和更高的主体保真度,适合需要绝对精确的商业场景。
📋 Nano Banana Pro vs Nano Banana 2 对比表
| 对比维度 | Nano Banana Pro | Nano Banana 2 |
|---|---|---|
| 底层架构 | Gemini 3 Pro | Gemini 3.1 Flash |
| 核心优势 | 极致精准度、复杂场景推理 | 速度快、性价比高 |
| 生成速度 | 较慢(约10-15秒) | 极快(约3-5秒) |
| 适用场景 | 商业交付、精细替换 | 快速迭代、日常创作 |
| 多图输入 | 最多14张 | 最多14张 |
| 分辨率 | 最高4K | 最高4K |
| 订阅要求 | Google AI Ultra / Pro | 免费用户有限额度 |
2.2 可灵AI 3.0 / 即梦Seedance 2.0——视频合成引擎
这两款是当前国产AI视频模型的第一梯队,它们的”多图参考”和”多模态输入”能力是我们方案的关键。
可灵AI 3.0(快手)
-
全球首创”主体参考”:上传多图/视频作为主体参考,精准锁定核心视觉元素
-
多图参考生视频:支持1-4张参考图,框选指定区域(人物/动物/物品/场景)
-
原生4K直出:2K/4K像素级直出,无需二次放大
-
智能分镜:AI自动调度景别与机位,支持3-15秒灵活时长
-
局部参考控制:框选图片中特定区域,避免无关元素干扰
即梦Seedance 2.0(字节跳动)
-
多模态混合输入:单次生成可组合最多9张图片 + 3段视频 + 3段音频 + 文本
-
@标签参考语法:通过
@图片1、@视频1精确指定每个素材的用途 -
总文件上限12个:所有模态文件总数不超过12
-
首尾帧精准控制:支持首帧/尾帧模式,锁定起止画面
-
最高2K分辨率,最长15秒:满足短视频创作需求
| 对比维度 | 可灵AI 3.0 | 即梦Seedance 2.0 |
|---|---|---|
| 参考图数量 | 1-4张(支持框选区域) | 最多9张 |
| 视频参考 | 支持视频主体参考 | 最多3段(总15秒) |
| 音频输入 | 支持音色克隆(3-8秒人声) | 最多3段MP3 |
| 输出分辨率 | 最高4K | 最高2K |
| 输出时长 | 3-15秒 | 4-15秒 |
| 核心优势 | 写实画质、主体锁定极强 | 多模态组合灵活、运镜复刻精准 |
| 最适场景 | 高品质商业广告、仿真人 | 多素材组合创意、模版复刻 |
不过以上说到的这几点,我们都可以利用献丑AI去更简单的通过节点的方式解决:
三、方案A:逐帧锁定法(商业级 / 高精度场景)
适用场景:高端产品广告片、品牌TVC、甲方要求”逐帧无瑕疵”的商业交付项目
核心逻辑:先生成一段包含正确动作路径的”底板视频”(允许产品形变),再对每个关键帧进行精确的产品替换重绘,最后用多图参考合成最终视频。
步骤1:获取动作底板视频
首先,我们需要一段关于公司产品的原始视频。此阶段不追求产品细节的完美,只需要:
-
✅ 模特的动作自然准确
-
✅ 产品在画面中的空间位置正确
-
✅ 整体光影环境合理
以”鸣扬高创公司”为例,使用献丑AI生成一段基础视频。

@图片1 是场景图, @图片2 是小女孩三视图,@图片3 是爸爸三视图, @图片4 是水质在线监测站未打开的样子,@图片5 是监测站打开门之后的样子。请生成以下镜头: 镜头1:背对镜头跟随拍摄,低角度特写小女孩和爸爸走在小女孩和爸爸走向水质在线监测站的脚步特写 镜头2:爸爸背对镜头,前景是小女孩的背影,中景是爸爸站在监测站的背影。此时的监测站是未打开的样子 镜头3:特写爸爸的手从监测站左侧打开监测站的门,然后特写监测站打开的样子。 这是一个温情走心的保护水质公益主题视频,节奏舒缓,无大幅度运镜,写实风格,高级感纪录片风格,无背景BGM,真实的音效。
[rihide]
[/rihide]
💡 Tips:此阶段即使监测站上的文字模糊、或者有轻微形变都不要紧——我们只需要这段视频中模特手部的运动轨迹和产品的空间坐标。(当然这个视频是720分辨率,不高,但是效果足以)
步骤2:按分镜节点抽取关键帧
将这段原始视频导入剪辑工具(剪映、Premiere、达芬奇等),按照以下原则导出静帧:
-
动作转折点:手臂抬起的最高点、旋转的起始/终止角度
-
镜头切换点:推近/拉远/平移的起止帧
-
画面变化大的节点:产品朝向发生明显变化的帧
一般5-10秒的视频,抽取 5-8个关键帧 即可。
⚠️ 注意:关键帧之间的间距要相对均匀。如果某段运动特别剧烈(如快速翻转),需要增加该区间的帧密度。(我们把有问题的帧都截取)

步骤3:Nano Banana Pro逐帧产品重绘
这是整个工作流中精度要求最高的环节。
操作方法:将每张关键帧图片 + 你的产品标准图(如品牌方提供的产品高清正面照)一起上传至 献丑AI,然后可以利用涂鸦功能框选要调整的细节
针对每个关键帧的专业提示词模板:
如果你是替换产品可以用下面这段提示词
将画面中人物手持的物体替换为图2中的【产品名称】。要求: 1. 产品上的文字/Logo保持清晰完整可读 2. 材质质感与图2保持一致(具体描述:哑光/高光/磨砂/金属等) 3. 产品在画面中的角度与原图一致,根据该角度合理推算产品的透视关系 4. 手指与产品的接触点和遮挡关系保持原图状态不变 5. 光照方向和反光高光位置与原图场景环境光一致
如果你是修改某处细节,可以用我下面的方式👇
涂鸦框选要替换的logo位置

给下方的提示词
@图片2 红色标记区域换成@图片1 logo,logo大小在红色区域内,最后画面去掉红色标记
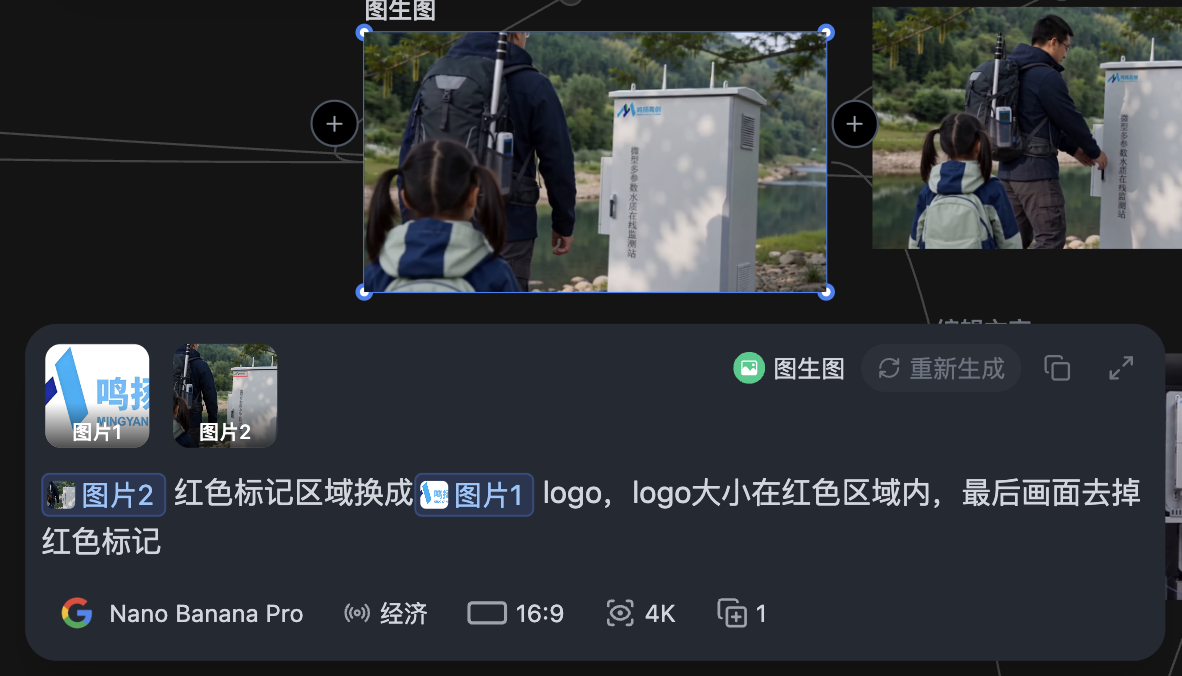
此时效果是这样的

逐帧替换时的关键要点:
-
每一帧都单独上传原始关键帧 + 同一张产品标准图
-
确认每帧生成的结果中,产品角度与原始帧中的空间位置吻合
-
若某帧替换效果不理想,调整描述词后重新生成,直至满意
步骤4:多图参考合成最终视频
将完成重绘的所有关键帧图片,作为参考序列输入可灵AI 3.0 或即梦Seedance 2.0。
在献丑AI中的可灵AI 3.0中的操作:
选择”参考生视频”模式,选择”可灵3.0模型”,上传重绘后的关键帧序列(按时间顺序排列),配合以下提示词:
根据上传的参考图片序列(按时间顺序排列),生成一段连贯的产品展示视频。要求: 1. 严格按照参考图中产品的角度变化和位置移动进行过渡 2. 人物的动作、表情、服装与参考图完全一致 3. 产品上的"鸣扬高创"文字在全程保持清晰稳定,不可变形或模糊 4. 镜头运动平滑,帧间过渡自然 5. 产品遵循物理规律,具有真实的体积感和碰撞关系,不可出现融化或飘浮
在即梦Seedance 2.0中的操作(使用@语法):
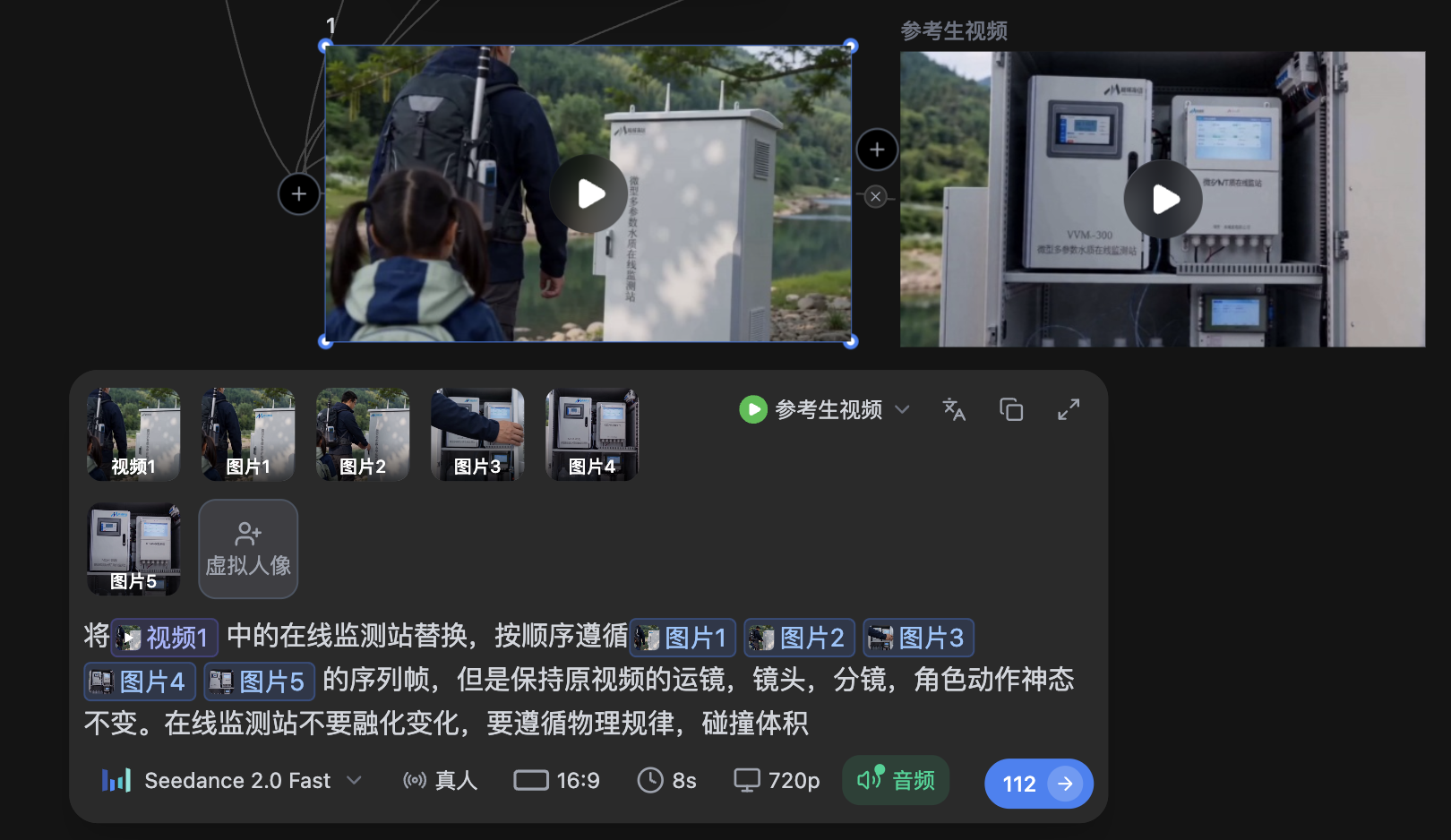
进入”全能参考模式”,上传所有关键帧图片,输入:
按照 @图片1 → @图片2 → @图片3 → @图片4 → @图片5 的顺序作为时间线关键帧,生成一段连续的产品展示视频。保持各帧之间的人物动作和产品角度平滑过渡,产品表面文字和材质在全程锁定不变。运镜平稳,产品具有真实碰撞体积。
[rihide]
[/rihide]
💡 原理解析:为什么这样做有效?因为我们在时间轴上每隔1-2秒就注入了一个”完美标准答案”,AI只需要在两个确定性极高的关键帧之间做”补间过渡”——它的自由发挥空间被从”整段视频”压缩到了”两帧之间的极短片段”,随机性偏差被锁死在可控范围内。
四、方案B:黄金单帧法(效率优先 / 日常场景)
适用场景:自媒体短视频发布、创意方案初步验证、产品运动幅度有限(无大幅翻转/大角度旋转)的内容
核心逻辑:用Nano Banana Pro精心打造一张”完美首帧”,以这张高质量图片为锚点统领整段视频的生成。
步骤1:选择最优单帧
从原始视频中截取产品细节最清晰、角度最具代表性的一帧。选择标准:
-
✅ 产品正面/最重要面朝向镜头
-
✅ 产品在画面中占比适中,不过大或过小
-
✅ 光线均匀,无过度曝光或阴影遮挡
以”模特佩戴某品牌智能手表走过都市街头”为例,选取一帧手表表盘面向镜头的中景画面。
一名年轻男子走在现代都市街道上,中景镜头,他的左腕微微抬起,露出一块黑色智能手表,圆形表盘面向镜头,手表显示蓝色数字界面,黑色硅胶表带,穿着休闲装,衣袖卷起露出手腕清晰可见,背景中的城市建筑和行人模糊不清,自然光下,黄金时段的温暖色调,街头时尚摄影风格,浅景深聚焦于手表部位,高分辨率,真实感十足

步骤2:Nano Banana Pro 单帧深度重绘
上传这张单帧 + 品牌手表的官方产品图,执行替换:
将画面中人物左手腕上的手表替换为图2中的智能手表。要求:表盘界面显示与图2一致,表带材质为图2中的银色链条,表冠细节清晰可见,整体质感与图2产品图保持一致。手腕姿态和袖口遮挡关系不变。
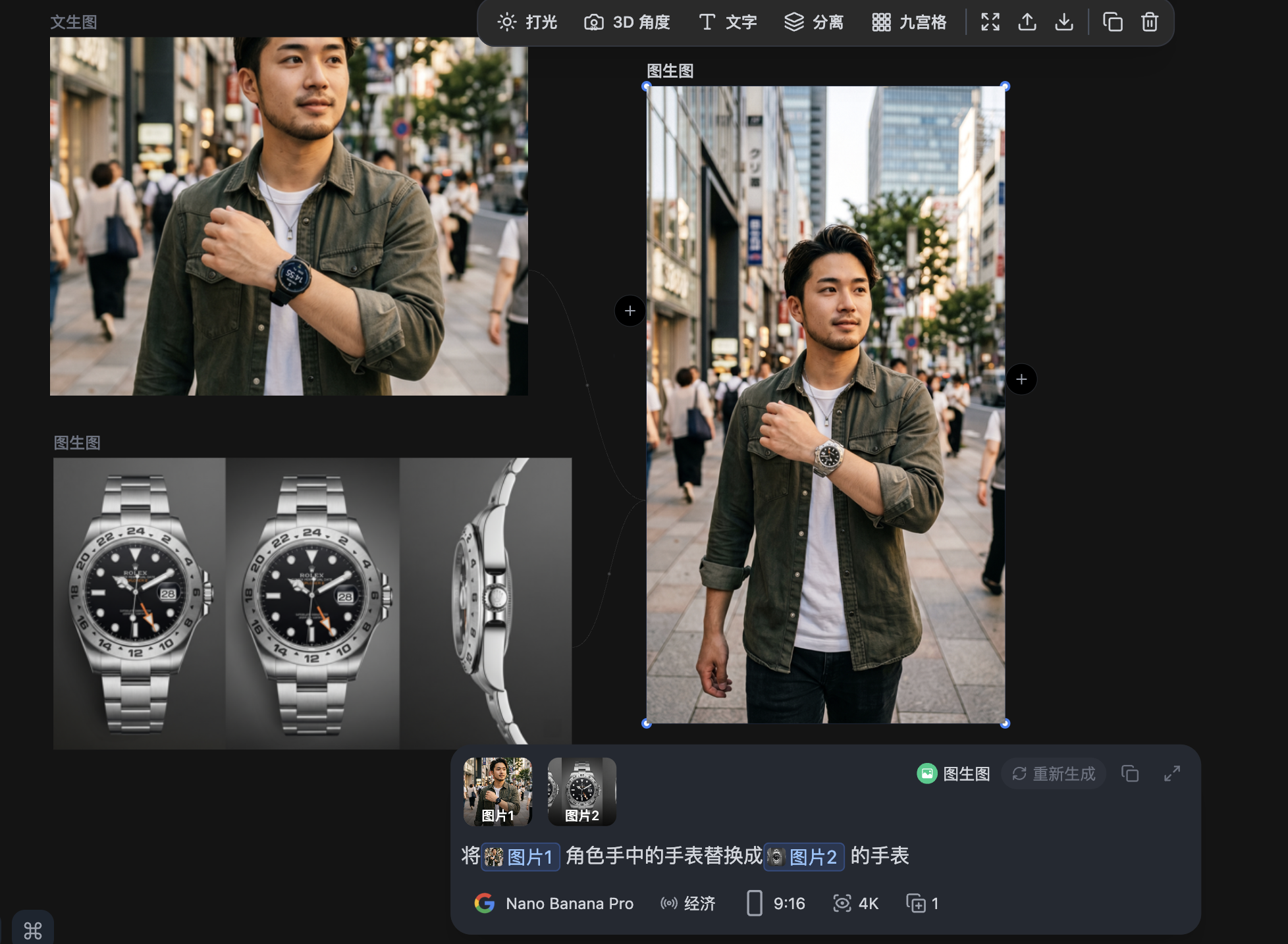
仔细检查生成结果:
- 表盘上的UI界面是否清晰
- 表带颜色和纹理是否匹配
- 表冠和按键是否存在
- 光影反射是否与环境一致
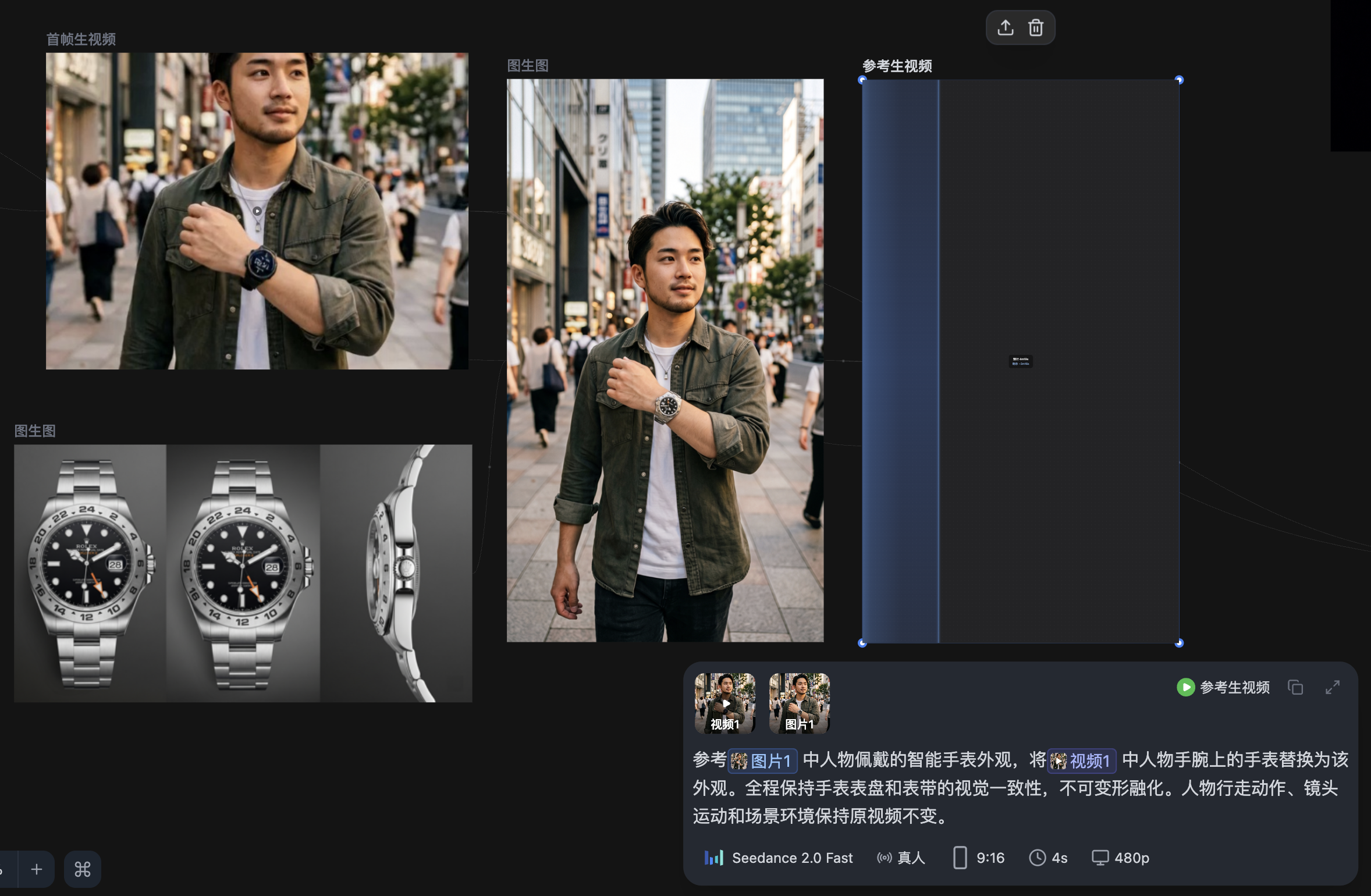
步骤3:单帧 + 原始视频 → 合成
将重绘后的”黄金单帧” + 原始动态视频一起提交给视频模型。
可灵AI 3.0提示词:
参考上传图片中人物佩戴的智能手表外观,将视频中人物手腕上的手表替换为该外观。全程保持手表表盘和表带的视觉一致性,不可变形融化。人物行走动作、镜头运动和场景环境保持原视频不变。
即梦Seedance 2.0提示词(@语法):
参考 @图片1 中手腕上智能手表的外观,将 @视频1 中人物佩戴的手表替换为该款式。保持原视频的运镜和人物动作,手表外观在全程保持一致。
[rihide]
[/rihide]
适用边界与限制说明
⚠️ 何时不该使用黄金单帧法:
-
产品发生大角度旋转/翻转时——单一视角的参考图无法约束其他视角
-
产品是视频绝对主体时(如纯产品特写)——任何微小的不一致都会被察觉
-
视频时长超过8秒时——单帧的约束力会随时间显著衰减
💡 判断标准:如果产品在视频中的角度变化超过约45°,请切换至方案A的逐帧锁定法。
五、方法论提炼:”信息密度控制”的思维框架
5.1 一致性 = 控制信号密度 × 关键节点覆盖率
当你面对任何AI视频一致性问题时,不要急于寻找”一键解决”的按钮。正确的思考路径是:
需求分析 → 评估形变风险 → 选择控制策略 → 确定参考帧密度
方案选择决策树:
-
产品是否发生大幅度空间翻转?
-
是 → 方案A(逐帧锁定)
-
否 → 继续判断↓
-
是否为商业交付/高价值项目?
-
是 → 方案A
-
否 → 继续判断↓
-
视频时长是否 ≤ 5秒 且产品角度变化 ≤ 45°?
-
是 → 方案B(黄金单帧)
-
否 → 方案A
5.2 三个进阶原则
原则一:用确定性约束自由度
“给AI越精确的参考,它就越没有’犯错’的空间。”
这体现在提示词层面:不要用”把产品换成好看的”这种模糊描述,而是精确到材质、文字、角度、光影方向。在参考图层面:不要只给一张正面图,尽量提供产品在不同角度的视图。
原则二:参考帧间距决定过渡质量
关键帧之间的时间间距直接影响最终的过渡平滑度:
| 帧间距 | 过渡质量 | 适用场景 |
|---|---|---|
| 每0.5秒一帧 | ⭐⭐⭐⭐⭐ 极优 | 快速旋转/复杂运动 |
| 每1秒一帧 | ⭐⭐⭐⭐ 优秀 | 中速平移/小幅旋转 |
| 每2秒一帧 | ⭐⭐⭐ 良好 | 缓慢移动/近乎静止 |
| 仅首尾帧 | ⭐⭐ 一般 | 极简运动/测试用途 |
原则三:提示词中的物理约束语句
在最终合成视频的提示词中,务必加入物理约束描述,这能显著降低模型的”自由发挥倾向”:
# 物理约束关键词示例(加入提示词尾部) 产品遵循真实物理规律: - 具有真实的碰撞体积,不可穿模 - 材质表面反光随环境光自然变化 - 不可出现融化、扭曲、液化效果 - 产品边缘清晰锐利,不可出现羽化溶解
5.3 未来趋势展望
随着可灵AI 3.0的”主体参考”和即梦Seedance 2.0的”多模态@语法”不断迭代,AI视频一致性问题正在被从模型层面自上而下地解决。但在当前阶段(2026年),模型原生能力尚无法做到”给一张图就能保证10秒视频零形变”——人工干预关键帧仍然是商业级品质的必经之路。
可以预见的演进方向:
-
原生3D感知:模型内置产品三维理解能力,从根本上消除形变
-
跨镜头记忆系统:多段视频之间共享”产品身份ID”
-
实时一致性校验:生成过程中自动检测形变并回滚修正
总结与行动清单
📌 三个核心要点
-
形变的本质是扩散模型概率采样中的随机性偏差——不是模型的Bug,而是信息论层面的信噪比问题
-
解决思路不是找”更强的模型”,而是在时间轴关键节点注入足够密度的确定性参考信号
-
两套方案分级使用:商业交付用”逐帧锁定”(方案A),日常创作用”黄金单帧”(方案B)
✅ 5步立即行动指引
-
注册工具账号:开通献丑AI账号,初始赠送100积分,相当于50张 Banana pro
-
准备产品素材包:收集产品高清图(正面/侧面/45°各一张),背景干净,分辨率不低于2K
-
生成一段测试底板:用任一视频模型生成一段5秒的产品展示视频(接受形变)
-
执行一轮方案B练习:截取首帧 → Nano Banana Pro替换 → 提交合成 → 评估效果
-
升级至方案A:对同一段视频,抽取5个关键帧 → 逐帧替换 → 多图参考合成 → 对比方案B的效果差异
🔗 工具链接汇总
| 工具 | 链接 | 用途 |
|---|---|---|
| 献丑AI | https://xianchou.com/ | 献丑AI 创作平台 |
| 可灵AI | https://klingai.com | 多图参考视频生成 |
| 即梦AI | https://jimeng.jianying.com | Seedance 2.0 多模态视频生成 |
最后一句话:AI视频一致性的战场,胜负不在于你使用了多”高级”的模型,而在于你是否理解了“信息密度决定一致性”
发表回复