
从”祈祷式出图”到”像素级操控”的AI空间控制完全指南
你是否经历过这样的挫败——提示词写得滴水不漏,AI却把该站左边的人丢到了右边,该跑起来的角色原地不动?问题不在你的文字功底,而在于扩散模型天生的”空间失聪症”。本文将揭示其底层原因,并教你一套零门槛的”图像锚定策略”,让你仅凭一张手绘草图,就能精准控制单人/多人的站位、姿态与运动轨迹——把AI画面的主导权,真正夺回到自己手中。
一、诊断篇——AI为什么”听不懂”你的位置指令?
在试图修复问题之前,我们必须先理解问题的根源。许多创作者反复尝试用更精确、更冗长的位置描述来约束AI,结果发现收效甚微。这并非工具的Bug,而是由底层技术架构决定的。[rihide]
目前主流的AI图像/视频生成工具(无论是即梦AI、可灵、海螺AI,还是Midjourney、Nanao Banana,GPT image 2),其底层架构大多基于扩散模型(Diffusion Model)。
扩散模型的核心工作流程可以简化为:从一堆随机噪点出发,根据你的提示词,一步一步地”擦除”噪点,最终”雕刻”出一幅清晰画面。 在这个逐步去噪的过程中,模型通过一个关键机制来理解你的文字——交叉注意力(Cross-Attention)。
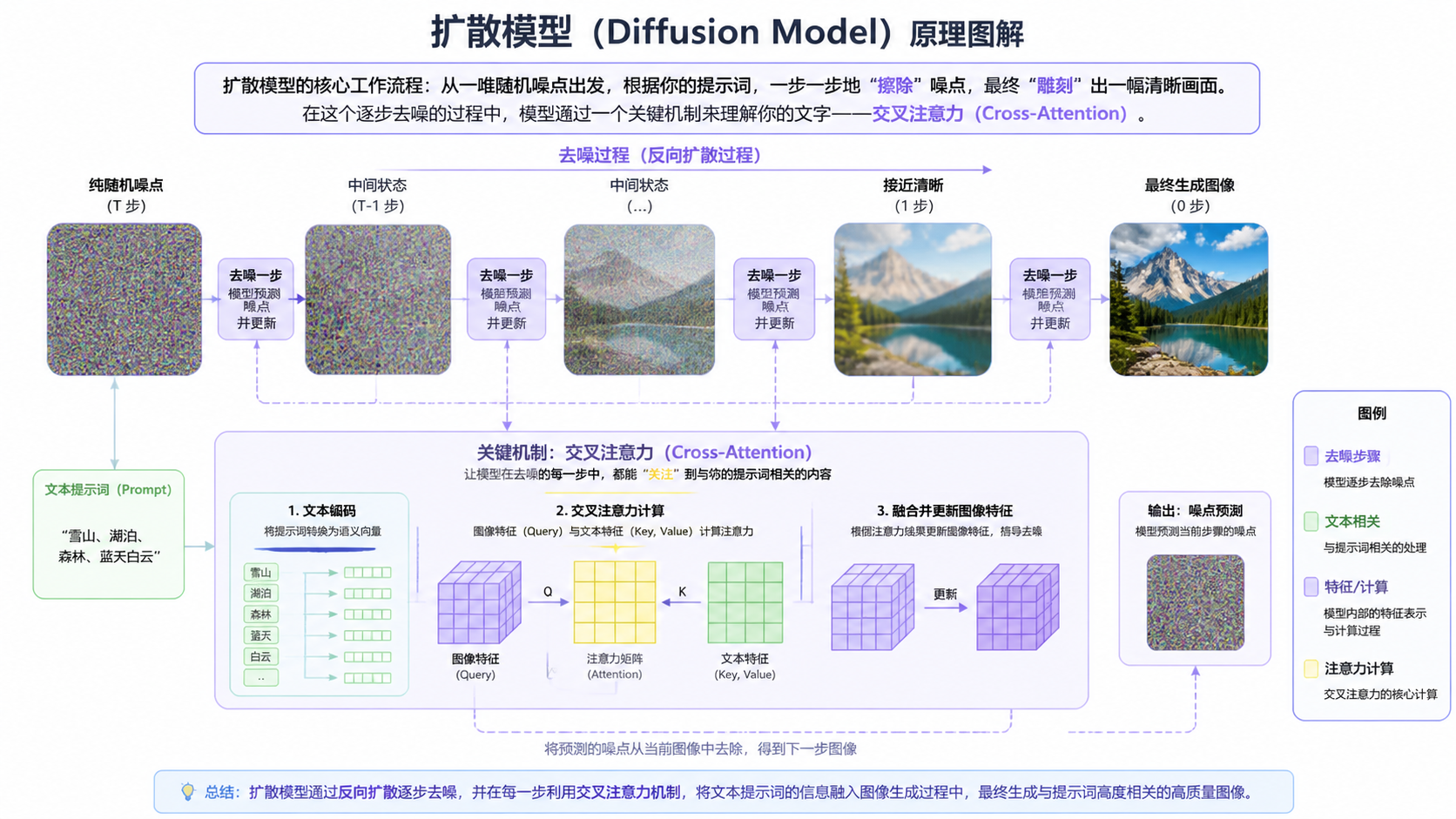
交叉注意力的工作方式是:
-
将你的文字提示词编码为一组语义向量(Key & Value);
-
将正在生成的图像特征编码为一组查询向量(Query);
-
图像的每一个像素位置,都会去”询问”文本中的每一个词——”我应该长什么样?”
这里就是问题所在。 交叉注意力天然擅长匹配的是“特征”信息——比如”红色的裙子”、”卷发”、”夕阳的光影”这类视觉属性。而当你写下”站在画面左侧三分之一处”这种空间坐标信息时,它在从文本到语义向量的编码过程中会被严重衰减。
打个比方:交叉注意力机制就像一个只关心”穿什么衣服、长什么脸”的选角导演,你跟他说”请站到舞台左边”,他可能根本没听见——因为他全部注意力都在打量演员的造型。[/rihide]
1.2 一组对比实验:纯文字位置描述到底有多不可靠?
为了让你对这个问题有直观感受,我们设计了一组简单的对比:[rihide]
| 对比维度 | 🔴 实验组A:不描述位置 | 🟢 实验组B:详细描述位置 |
|---|---|---|
| 提示词 | 一位身穿白色汉服的女子,一位身穿黑色西装的男子,站在故宫太和殿前,正午阳光 |
一位身穿白色汉服的女子站在画面最左侧,一位身穿黑色西装的男子站在画面最右侧,两人之间保持明显距离,故宫太和殿前,正午阳光 |
| 预期结果 | 两人位置随机 | 女子在左,男子在右,保持距离 |
| 实际结果 | 两人位置随机(符合预期) | 两人仍然大概率紧挨在一起,或位置与描述不符 |
| 位置准确率 | — | 约 20%~35%(需多次重试) |
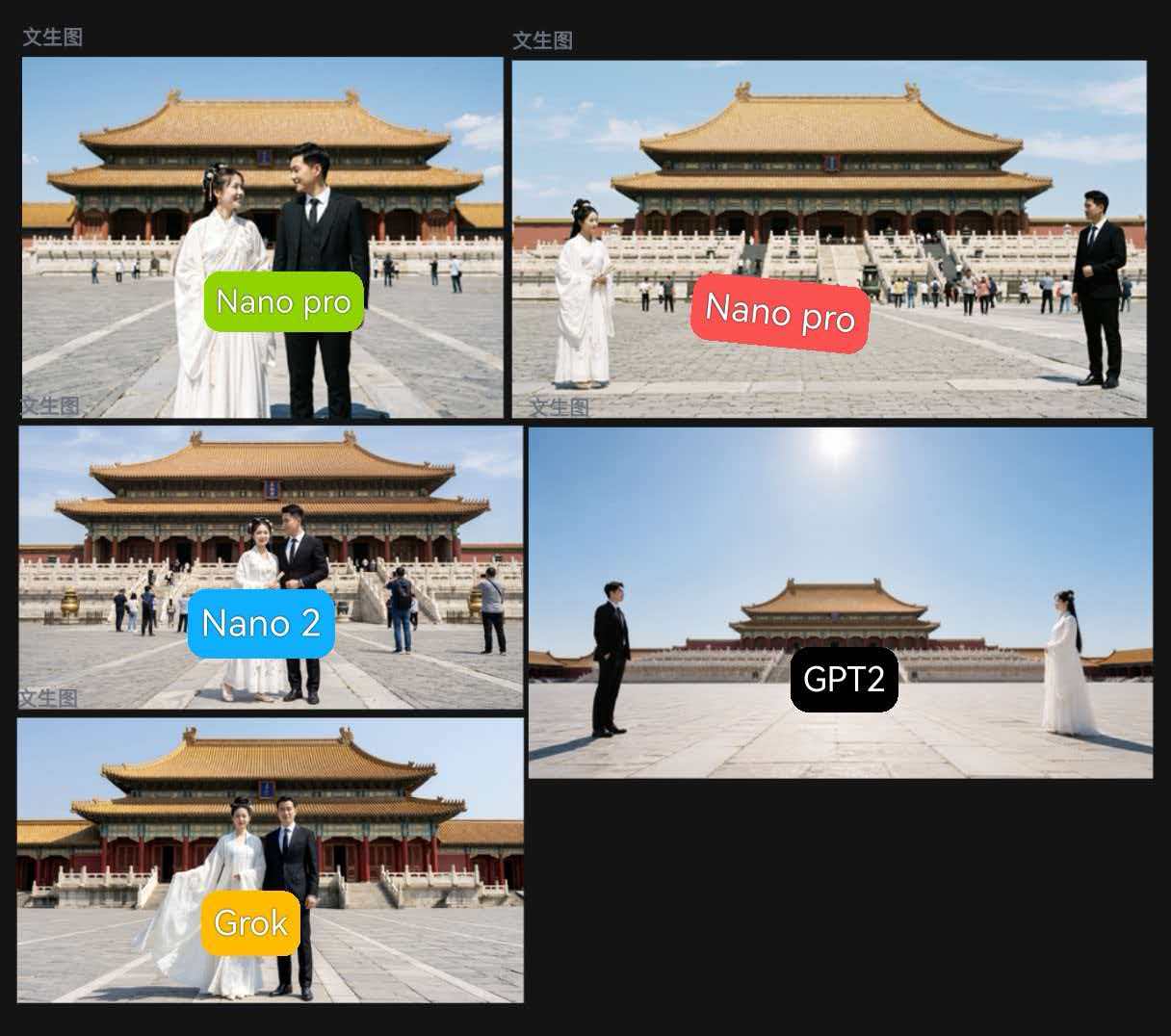
核心结论:
纯文字的空间描述对扩散模型来说,是一种极其微弱的信号。 文本在传递”红裙子”这种特征时信号强度为100%,而在传递”站在左边”这种空间信息时,信号强度可能只有20%~30%。用文字控制位置,本质上是在”碰运气”。[/rihide]
1.3 核心洞察:信号强度决定控制力
理解了上述原理后,解决思路也就清晰了:[rihide]
既然文本的空间信号太弱,我们就需要找到一种信号强度远超文本的方式来传递位置信息。
在AI生成的世界里,什么东西的空间信号最强?答案是——图像本身。
当你给AI一张参考图时,图上的每一个像素都在精确地占据着一个空间位置。一个画在图片左下角的红色方块,对于AI来说就是一个像素级别的、不可忽视的强信号。这比你用语言描述”请在左下角放一个红色方块”要强上几个数量级。

这就是本文核心方法——“图像锚定策略”——的底层逻辑。[/rihide]
二、原理篇——”图像锚定策略”为什么能降维打击?
2.1 方法定义:什么是”图像锚定策略”?
图像锚定策略是指:利用在参考图像上叠加的视觉标记(彩色方框、箭头、编号等),将空间位置和运动轨迹信息转化为像素级的强信号,迫使AI在生成过程中遵循标记所指定的区域和路径。[rihide]
通俗地说:你在图上画个框,AI就知道在那儿放人;你画条箭头,AI就知道让人沿着那条路走。
这个方法的精髓在于——你不需要学习任何复杂的坐标系统、节点工具或代码参数。你只需要会用手机自带的画图工具画框和画线,就能”指挥”AI。
2.2 底层原理:图生图流程中的”注意力锚定”效应
为什么在图上画几个彩色框就能控制AI?这与图生图(Image-to-Image)的技术流程直接相关:
-
当标注图作为参考图输入时,AI会将这张图编码到潜在空间(Latent Space) 中。此时,你画的彩色框/箭头同样被编码为潜在空间中的一组特征。
-
彩色标记在潜在空间中占据了确定的像素区域。与周围区域相比,这些彩色标记具有显著不同的色彩特征,因此AI在降噪过程中会自然地将它们识别为”兴趣区域”。
-
配合文字提示词,你告诉AI”红色框里放A角色,蓝色框里放B角色”,就实现了视觉信号(像素位置)+ 语义信号(角色身份)的双重锁定。
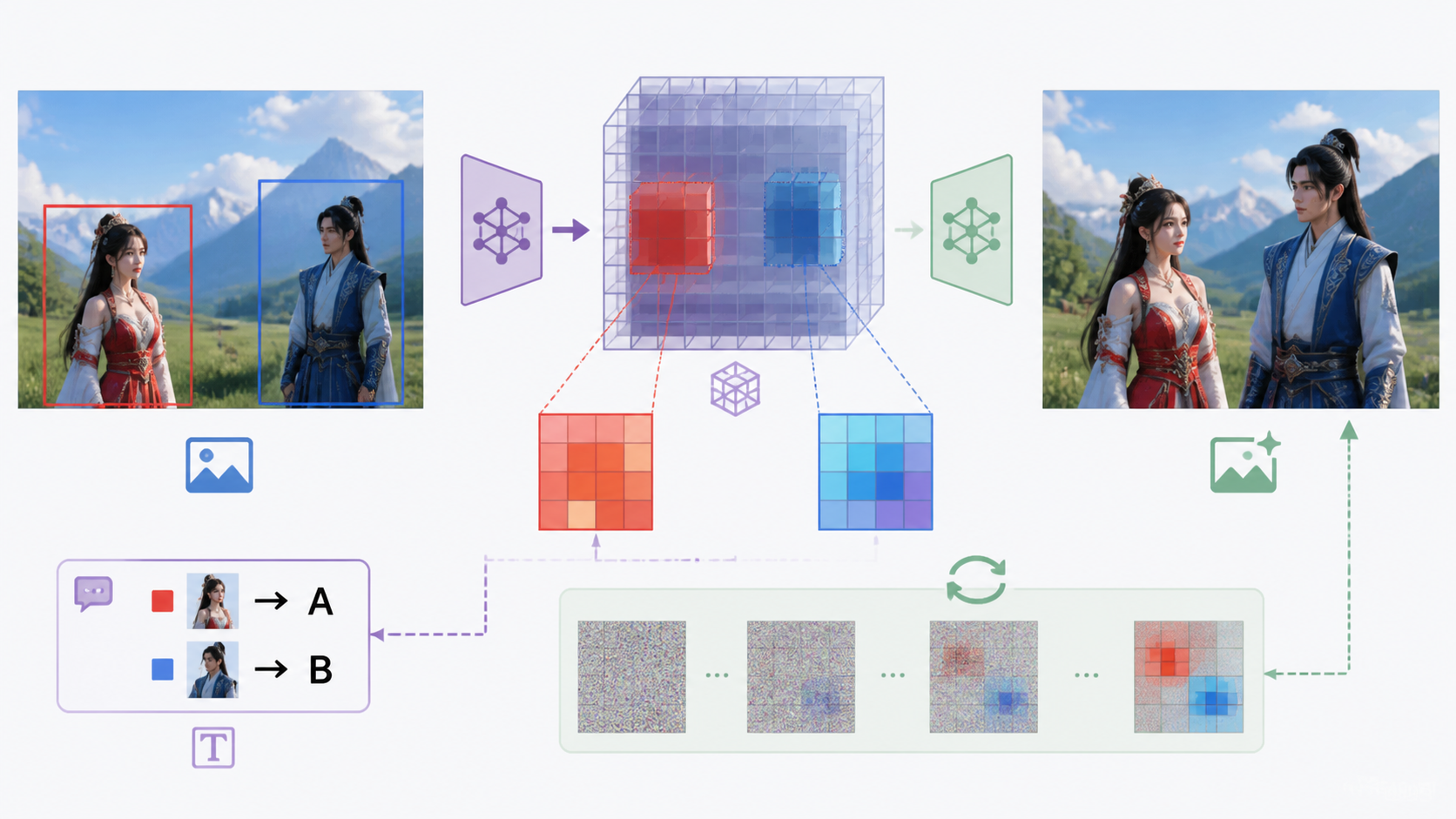
💡 一句话总结:画框/画线的本质,是用图像像素在潜在空间中”占位”,为AI提供了一个比任何文字描述都要强烈得多的空间先验。[/rihide]
2.3 适用范围:哪些AI工具能用这套方法?
核心条件:只要该AI工具支持“参考图/垫图/图生图”功能,这套方法就能使用。
| 工具名称 | 是否支持 | 推荐使用场景 |
|---|---|---|
| 即梦AI(Seedream) | ✅ | 图像生成、视频生成 |
| 可灵AI | ✅ | 视频生成(运动轨迹控制) |
| 海螺AI(MiniMax) | ✅ | 视频生成(含主体参考) |
| Midjourney | ✅ | 图像生成(–cref/–sref模式) |
| 献丑AI | ✅ | 进阶精确控制 |
| Nano Banana Pro | ✅ | 图像生成 |
⚠️ 注意:不同工具对参考图的解读方式和遵循程度有差异,效果好坏与工具的图像理解能力直接相关。本文的案例以献丑AI为主进行演示,但方法论对其他工具同样适用。
三、实操篇(上)——静态画面的角色精准站位
3.1 单角色定位:三步标准流程
掌握以下三个步骤,你就能让AI把任意角色放到画面中你指定的精确位置。[rihide]
📌 步骤1:生成纯净空镜
首先,生成一张不包含任何人物的纯场景底图(即”空镜头”)。这一步非常关键——空镜头将作为你的”画布”,后续所有角色都将被”放置”在这张画布上。
古风庭院全景,飞檐翘角的凉亭坐落在画面中央,亭下石桌石凳, 庭院中一棵老松苍劲,青石小径蜿蜒通向远处的门廊, 傍晚时分,夕阳余晖洒满院落,无人物,清晰空镜

💡 Tips:在提示词中明确写上”无人物”或”空镜”,防止AI自行添加人物。
📌 步骤2:人工标注位置
打开任意画图工具(手机截图编辑器、Windows画图、Photoshop均可),在空镜底图上用一个鲜明的彩色方框标出你希望角色出现的位置。

标注要点:
-
方框大小应约等于你期望角色在画面中占据的比例
-
使用高饱和度纯色(如大红色),确保AI能识别
-
线条粗细适中(建议5px~10px),太细AI会忽略,太粗会影响画面
📌 步骤3:带图生成——组合参考图 + 文字指令
将以下材料一起提交给AI:
-
图1:你希望出现在画面中的角色参考图
-
图2:画了标记的空镜底图
-
文字提示词:明确告诉AI标记与角色的对应关系
请将图1中的人物放置在图2中红色方框标注的位置上, 人物呈倒挂金钩姿势悬挂在凉亭翘角处 光影与场景自然融合,最终画面中不要出现红色方框

🔍 效果对比:为什么图像锚定完胜纯文字描述?[/rihide]
| 对比维度 | 🔴 纯文字描述法 | 🟢 图像锚定策略 |
|---|---|---|
| 提示词 | “一位白衣仙侠角色倒悬在古风庭院凉亭的右侧翘角处” | “将图1人物放置在图2红色方框位置倒悬” + 标注图 |
| 位置准确率 | ~25%(反复抽卡才能碰到对的位置) | ~85%+(首次生成即可精准定位) |
| 所需尝试次数 | 5~15次 | 1~3次 |
| 操作额外耗时 | 无 | 画框30秒 |
| 综合效率 | ❌ 低效 | ✅ 高效 |
3.2 多角色编排:”色彩编码分配法”
当画面中需要出现两个或更多角色,且每人有不同的站位和姿态时,挑战升级——如果你只用同一个颜色画多个框,AI极有可能把A角色放到B的位置上。
解决方案:为每个角色分配一个独立的颜色标识,然后在提示词中建立”颜色-角色”的一一对应关系。
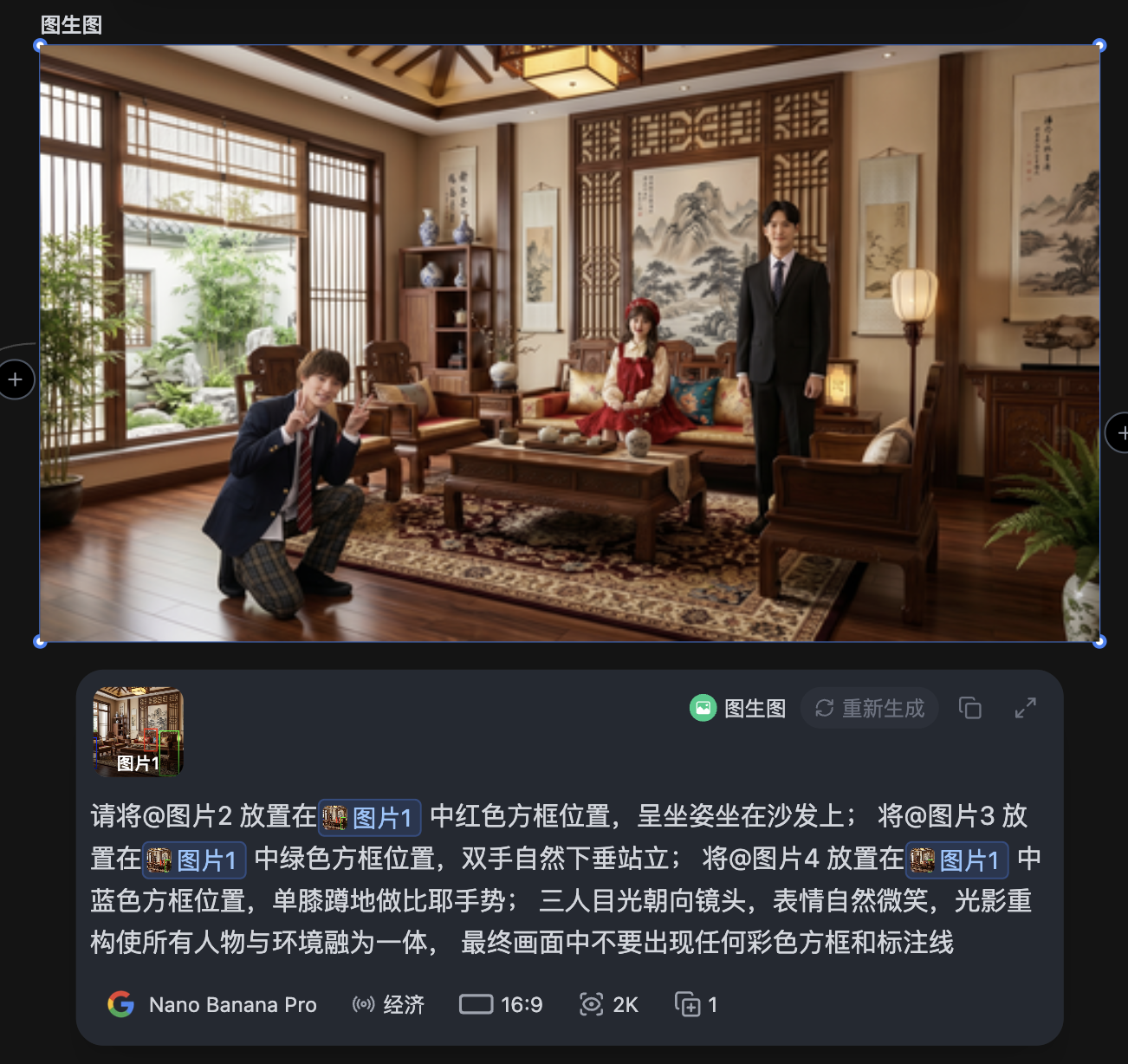
🎬 实战案例:中式客厅三人合影
场景设定:一个温馨的中式客厅,需要放置三个角色——红裙女孩坐沙发左侧、西装男士站中间背景处、校服男孩蹲右前方。[rihide]

操作步骤:
-
生成中式客厅空镜底图
-
在底图上分别用红色框、绿色框、蓝色框标出三个角色的位置
-
准备三张角色参考图
-
输入以下提示词:
请将角色A(图2,红裙女孩)放置在图1中红色方框位置,呈坐姿坐在沙发上; 将角色B(图3,西装男士)放置在图1中绿色方框位置,双手自然下垂站立; 将角色C(图4,校服男孩)放置在图1中蓝色方框位置,单膝蹲地做比耶手势; 三人目光朝向镜头,表情自然微笑,光影重构使所有人物与环境融为一体, 最终画面中不要出现任何彩色方框和标注线

💡 Tips:
色块数量建议不超过4个,过多会导致AI混淆
颜色选择上,优先使用红、绿、蓝、黄等高饱和度纯色,避免使用淡色或相近色
每个色块之间保持一定距离,不要重叠[/rihide]
3.3 提示词模板与避坑指南
为了帮你快速上手,这里提供经过反复验证的通用提示词模板:
模板一:单角色定位
将[图A]中的人物放置在[图B]中[颜色]方框标注的位置上, 人物姿势为[具体姿势描述],光影与场景自然融合, 生成画面中不要出现[颜色]方框
模板二:多角色编排
图1为场景底图,图2/图3/图4分别为角色A/B/C的参考图。 请将角色A放置在图1的[颜色1]方框处,[姿势描述]; 将角色B放置在图1的[颜色2]方框处,[姿势描述]; 将角色C放置在图1的[颜色3]方框处,[姿势描述]; 所有人物与场景光影重构,保持真实感,去掉所有颜色标注框
⚠️ 常见避坑要点:
| 问题现象 | 原因分析 | 解决办法 |
|---|---|---|
| 最终画面中仍带有彩色框线 | 提示词中未强调去除 | 在提示词末尾明确写明“去掉框线/标注”,或在负面提示词中排除 |
| 角色出现在错误的色块位置 | 颜色-角色对应关系描述不够清晰 | 使用”图[编号]的角色→[颜色]框”的明确格式 |
| 角色大小比例失调 | 色块大小与期望的角色比例不匹配 | 画框时就按照角色应占的画面比例来设定框的大小 |
| 角色与背景光影不协调 | 参考图光影方向与底图差异过大 | 在提示词中强调”光影重构”或”光影融合” |
四、实操篇(下)——视频生成的角色运动轨迹控制
掌握了静态图的站位控制后,进阶到视频中的运动轨迹控制只需要多做一步——把”框”换成”箭头”。[rihide]
4.1 单角色运动:箭头轨迹法
原理:用一条带方向的箭头线画在空镜底图上,AI会将其理解为角色的运动路径,并据此生成运动画面。
🎬 实战案例:人从沙发起身绕过茶几走到另一侧
场景设定: 一个普通家庭客厅,一位男性坐在画面中间的沙发上,沙发前方有一张矩形茶几挡住了去路,画面右侧是另一张单人沙发。
步骤1:生成包含人物的起始画面
提示词:
普通家庭客厅全景,一位穿灰色卫衣的年轻男性坐在画面中央的 米色三人沙发上,沙发正前方摆着一张矩形木质茶几, 茶几上放着水杯和遥控器,画面右侧有一张棕色皮质单人沙发, 两张沙发之间的通道被茶几堵住,必须绕行才能通过, 自然室内光线,正面全景机位

💡 关键点: 这里茶几的位置特意设定为”堵住直线路径”,这样才能测试出轨迹标注是否真的有效——如果AI只看终点不看路径,人物就会直接”穿过”茶几。
步骤2:在画面上标注运动路径
把生成好的图片导入任意画图工具,用红色粗箭头画出一条明确绕过茶几的弧线路径:
从男性所坐位置出发 → 先向前走到茶几左侧 → 沿茶几边缘向右绕行 → 绕过茶几右侧角 → 最终到达右边单人沙发
在起点标注数字 “1”,终点标注数字 “2”。
步骤3:提交标注图 + 提示词
画面中坐在沙发上的男性起身,沿红色箭头所示轨迹(从标注A走向标注B)行走, 先向前走到茶几左侧(画面左侧),然后沿茶几边缘向右绕过茶几, 最终走到右侧单人沙发旁(绿色方框标记)坐下,步态自然随意,像是要换个位置坐, 画面中不要出现红色箭头和数字标注
我利用上面这个提示词,失败的原因不是这个标注的方式不好,而是提示词“右侧”二字对画面进行了影响,请看:
此时,男生直接就向右坐下
我们把提示词更改一下:
画面中坐在沙发上的男性起身,沿红色箭头所示轨迹(从标注A走向标注B)行走, 先向前走到茶几左侧(画面左侧),然后沿茶几边缘绕过茶几, 最终走到单人沙发旁(绿色方框标记)坐下,步态自然随意,像是要换个位置坐, 画面中不要出现红色箭头和数字标注
🔍 关键对比实验:画绕行路径 vs 不画路径
同样的场景、同样的起点终点,我们测试两种做法的效果差异:[/rihide]
| 对比项 | ❌ 不画路径,只写文字提示”走到右边沙发” | ✅ 画出绕过茶几的弧线路径 |
|---|---|---|
| 提示词 | “让男性起身走到右侧单人沙发坐下” | “让男性沿红色箭头轨迹绕过茶几走到右侧单人沙发沙发”(配标注图) |
| AI的典型表现 | 人物直接朝右侧沙发走直线,身体穿过茶几或茶几突然消失 | 人物先向前迈步,沿茶几边缘绕行,再走向右侧沙发 |
| 穿模/穿透概率 | 极高(~70%的生成结果中人会”穿”过茶几) | 大幅降低(人物明确绕行) |
| 运动路线合理性 | 不自然,像幽灵穿墙 | 符合真实生活中人的走路习惯 |
| 结论 | AI只理解了”起点→终点”,忽略中间障碍 | AI理解了”起点→绕行→终点”的完整路线 |
💡 这个实验说明了什么?
AI视频生成工具在没有路径标注时,默认走”两点之间直线最短”的逻辑。 它不会像人类一样自动判断”茶几挡路了,我应该绕开”。[rihide]
画出弧线轨迹的本质作用是:把你脑中”绕过障碍物”的空间意图,变成AI能看懂的视觉指令。
如果你只说”从A走到B”,AI给你最短路径(哪怕穿模); 如果你画出”从A绕一圈到B”,AI就会沿着你画的弧线运动。
⚠️ 关键提醒:必须要求AI去除标注线!
这一点在视频生成中尤为重要。如果你忘了在提示词中声明”画面中不要出现箭头”,AI就会把你画的红色箭头原封不动地”绘制”到视频画面中——变成一条悬浮在空中的红色光带,严重破坏画面效果。[/rihide]
4.2 多角色协同运动:”色彩隔离 + 编号轨迹”双保险法
当画面中有两三个角色需要执行不同方向的运动时,AI非常容易混淆——张三跑到了李四的路线上。这是因为多条同色箭头对AI来说几乎无法区分。
解决策略:结合两层信息区分——
-
色彩隔离:每个角色的运动箭头使用不同颜色
-
编号轨迹:每条箭头上标注起止编号(如红色1→2,蓝色1→2)
🎬 实战案例:街舞对决三人场景
场景设定:一个户外街舞广场,三位舞者各有不同的运动方式。[rihide]
标注方法:在空镜底图上画出:
-
红色箭头(1→2):从画面左侧滑向右侧
-
蓝色箭头(1→2):从画面右侧旋转滑向左侧
-
黄色圆圈(无箭头):标在画面中央偏后方,表示原地不动

画面中有三位人物,分别对应三种颜色标注: 红色标注舞者:沿红色箭头从位置A滑步移动到位置B,动作帅气有力; 蓝色标注舞者:沿蓝色箭头从位置A旋转移动到位置B,带有街舞地板动作; 黄色标注裁判:沿黄色箭头从位置A走动到位置B,观察比赛; 运镜保持稳定的中景机位,画面中不出现任何箭头、圆圈和数字标注
[/rihide]
🔍 效果对比:单色标注 vs 多色隔离标注
| 对比维度 | 🔴 全部用红色箭头标注 | 🟢 红/蓝/黄三色隔离标注 |
|---|---|---|
| AI理解难度 | 高(无法区分哪条箭头对应谁) | 低(颜色与角色一一对应) |
| 角色运动准确率 | ~30%(频繁出现角色”串线”) | ~75%+ |
| 生成废片率 | 极高 | 大幅降低 |
| 推荐度 | ❌ 不推荐 | ✅ 强烈推荐 |
五、进阶篇——提升控制精度的四个专业技巧
掌握了基础方法后,以下四个进阶技巧能帮你把成功率从”不错”提升到”优秀”。[rihide]
5.1 技巧一:空镜底图的质量把控
底图质量决定最终出图的上限。
空镜底图不仅仅是一个”背景”,它是整个画面的光影基底和空间参照。一张构图精良、光影合理的空镜,能让后续添加的角色更自然地融入场景。
具体建议:
-
为空镜生成多花一些提示词来描述光影、氛围和细节
-
生成3~5张空镜底图,从中选出构图和质量最佳的一张
-
检查底图中是否有”预留”好角色的站位空间(如一把空椅子、一段空旷的路面)
5.2 技巧二:标注精度与线条粗细的平衡
标注并非越精细越好,需要在可识别性和不干扰画面之间找到平衡:
| 标注要素 | 建议参数 | 说明 |
|---|---|---|
| 线条粗细 | 5~10像素 | 太细(<3px)AI可能忽略;太粗(>15px)会干扰画质 |
| 颜色选择 | 纯正红/绿/蓝/黄 | 避免淡粉、浅灰等低对比度色 |
| 框线形状 | 矩形框或粗箭头 | 避免复杂图形(圆形、星形),AI难以理解 |
| 标注数量 | ≤4组 | 超过4组色块,AI混淆概率急剧上升 |
5.3 技巧三:分步生成策略——先主后次,逐层叠加
对于3个以上角色的复杂场景,一次性全部放入往往效果不佳。更稳妥的方式是分步生成:
-
第一轮:空镜 + 标注 → 先放入主角(最重要的1~2个角色)
-
第二轮:以第一轮输出为新底图 → 标注剩余角色位置 → 加入次要角色
-
第三轮(如需):精修细节、调整光影一致性
这种”先主后次、逐层叠加”的方式,能显著降低多角色场景下的出错率。[/rihide]
5.4 技巧四:结合ControlNet或高级参考功能(进阶用户)
如果你使用的是Stable Diffusion + ControlNet这类专业工具链,可以在图像锚定策略的基础上进一步增强控制。例如:
-
使用Canny边缘检测或深度图(Depth Map) 作为额外的空间控制条件
-
调节参考图权重(Denoising Strength):权重越高,AI越严格遵循参考图的空间布局;权重越低,AI创作自由度越大
-
结合区域提示词(Regional Prompt) 功能,为不同区域指定不同的角色描述
⚠️ 这些进阶方法适用于有一定AI工具使用经验的用户。对于大多数创作者,前述的基础图像锚定策略已经足够应对90%以上的场景。
六、总结与行动清单
📌 全文四大核心要点
-
空间信号衰减是本质原因:扩散模型的交叉注意力机制天然更擅长匹配视觉特征而非空间位置,纯文字的位置描述信号极弱。
-
图像像素是最强的空间指令:在参考图上叠加彩色标注,能将空间信息从”微弱的文本语义”提升为”像素级的强制锚定”。
-
色彩编码是多对象控制的金钥匙:为每个角色/运动轨迹分配独立颜色,是防止AI混淆的最有效手段。
-
“去掉标注”是必写指令:务必在提示词中明确声明移除框线和箭头,否则它们会出现在最终画面中。
✅ 今天就能上手的三步行动
-
打开你常用的AI工具,先随便生成一张空镜底图(如”一间空旷的咖啡厅内景”)
-
用手机截图编辑功能,在底图上画一个红色矩形框
-
上传标注图 + 你的一张自拍/角色图,输入提示词:”将图1的人物放置在图2红色框位置,坐在咖啡厅的椅子上喝咖啡,光影融合,去掉红框”——观察效果
🏋️ 递进练习推荐
| 难度 | 练习内容 | 目标能力 |
|---|---|---|
| ⭐ | 单角色 + 单色框 + 空镜底图 | 掌握基础三步流程 |
| ⭐⭐⭐ | 双角色 + 红绿双色框 + 不同姿态 | 掌握色彩编码分配法 |
| ⭐⭐⭐⭐⭐ | 多角色 + 运动箭头 + 视频生成 | 掌握动态轨迹控制全流程 |
当你真正掌握了这套方法,你会发现自己的身份已经从一个”反复抽卡的祈祷者”,变成了一个”手持分镜稿的导演”。AI是你的演员和摄影团队,而你——是唯一的决策者。
发表回复