
用”画”代替”说”,将AI改图从概率游戏升级为确定性工作流
第一部分:问题诊断——你的AI改图为什么总在”开盲盒”?
1.1 一个你可能经历过的真实场景
假设你正在为一个茶饮品牌制作电商详情页。AI帮你生成了一张非常漂亮的场景图:木纹桌面上摆放着三杯不同口味的饮品,背景是柔和的暖光咖啡厅。一切都很完美,唯独最右边那杯饮品的杯口出现了一朵多余的装饰花,客户要求将其替换为一片薄荷叶。[rihide]
你的第一反应是什么?
大多数人会在文本提示词里这样写:
请把桌面上最右边那杯饮品杯口的装饰花去掉,换成一片新鲜的薄荷叶
结果呢?AI可能把中间那杯的吸管改没了,也可能把左边那杯的颜色改掉了,甚至可能整个桌面都被”刷新”了一遍。你反复修改了五六次,时间浪费了,最终效果还不如第一版。
这不是个例——这是绝大多数人在AI改图时遇到的核心痛点。
1.2 普通做法 vs 专业做法:一张对比表看清差距
| 对比维度 | ❌ 普通做法(纯文本描述) | ✅ 专业做法(视觉标注 + 精简文本) |
|---|---|---|
| 告诉AI改什么 | “把右边那杯饮品杯口的花换成薄荷叶” | 用画笔涂抹出花朵所在区域 |
| 告诉AI改成什么 | 混在同一段文字里 | 文本只写:”一片新鲜薄荷叶” |
| AI的理解难度 | 需要同时理解空间位置+物体特征+操作意图 | 位置已锁定,只需理解”生成什么” |
| 命中率 | 约20%-40%,多次抽卡才能成功 | 90%以上一次命中 |
| 对其他区域的影响 | 经常误改周边内容 | 严格限制在标注区域内 |
| 耗时 | 5-10分钟反复迭代 | 30秒内完成 |
关键结论:失败的根源不是你描述得不够好,而是你选错了和AI沟通的方式。[/rihide]
第二部分:原理拆解——AI到底是怎么”看图”和”改图”的?
理解底层逻辑,是掌握一切操作技巧的前提。这一章我们不堆公式,但要把”为什么视觉标注比文字更有效”这件事讲透。
2.1 扩散模型(Diffusion Model)的”视角”
当前主流的AI图像生成工具——无论是Midjourney、Gemini的Nano Banana Pro,还是即梦AI,GPT——其底层架构都属于扩散模型(Diffusion Model)家族。[rihide]
扩散模型的核心工作方式可以用一个类比来理解:
想象一张清晰的照片被不断撒上噪点沙粒,直到变成一片灰蒙蒙的噪声。扩散模型学会的,就是”如何一步步把沙粒吹走,还原出清晰图片”这个逆向过程。
在AI的”眼里”,一张图片不是”桌子上有三杯饮品”这样的语义场景,而是由数百万个像素点构成的数值矩阵。它不具备人类的空间常识——不知道”左边”和”右边”在哪里,不理解”旁边那个”指的是谁。
[ri-alerts color=”primary”]扩散模型原理我在之前的文章提到过,这里就不重新提了[/ri-alerts]
当你说”最右边那杯饮品杯口的花”,AI需要完成的推理链条是:
-
理解”最右边”→ 在像素空间中定位到哪个区域?
-
理解”饮品”→ 画面中有三杯,到底是哪一杯?
-
理解”杯口的花”→ 在那个区域中,哪些像素是”花”?
一旦画面中有多个相似物体、存在前后遮挡或光影变化,AI对这条推理链的解读就会产生歧义——你以为说得很清楚,但AI内部的概率分布可能同时”看中”了两三个候选目标。
2.2 提示词的三层权重体系:一个被多数人忽略的认知框架
这里要引入一个非常重要的认知模型,我把它称为“提示词三层权重体系”。理解这个体系,是从新手跨越到进阶用户的关键一步。
很多人以为”提示词”就是指你输入的那段文字。但事实上,在AI改图的完整工作流中,提示词至少包含三个层次,而且它们的权重并不相等:
| 层级 | 提示词类型 | 信息性质 | 权重等级 |
|---|---|---|---|
| 第一层 | 底图本身 | 整体上下文:构图、色调、光影、物体关系 | ⭐⭐⭐⭐⭐ |
| 第二层 | 视觉标注(遮罩/涂抹/标记点) | 空间坐标:精确告诉AI”在哪里操作” | ⭐⭐⭐⭐ |
| 第三层 | 文本提示词 | 语义指令:告诉AI”做什么/生成什么” | ⭐⭐⭐ |
底图的权重最高——它决定了整张图的基调,AI在修改时,会尽力保持与底图的风格、光影、色彩一致。
视觉标注的权重次之——但在”定位”这个任务上,它拥有绝对的统治力。当你用画笔把某个区域涂抹出来,就等于给AI画了一道”物理围栏”。AI只需要在围栏内执行任务,完全不需要去”猜”你说的是画面中的哪个位置。
文本提示词的权重最低——但它依然不可或缺,因为它负责告诉AI”在这个围栏里,我想要什么”。 💡 深入一步:为什么视觉标注的权重远大于文本?(技术原理简述)
在扩散模型的架构中,文本提示词通过交叉注意力机制(Cross-Attention)影响图像生成——简单来说,文本的语义信息被”注入”到去噪过程中,引导像素的生成方向。但这种引导是全局性的、概率性的,文本信息会被分散到整张图的所有区域。
而视觉标注(即遮罩/Mask)的工作方式完全不同。以局部重绘(Inpainting)为例,当你标注了一个遮罩区域后,模型会将遮罩图和被遮罩后的原图(Masked Image)直接拼接到输入张量中。这意味着遮罩信息是作为像素级的硬约束进入模型的——它不是在语义空间里”暗示”AI,而是在数据层面直接锁定了操作边界。
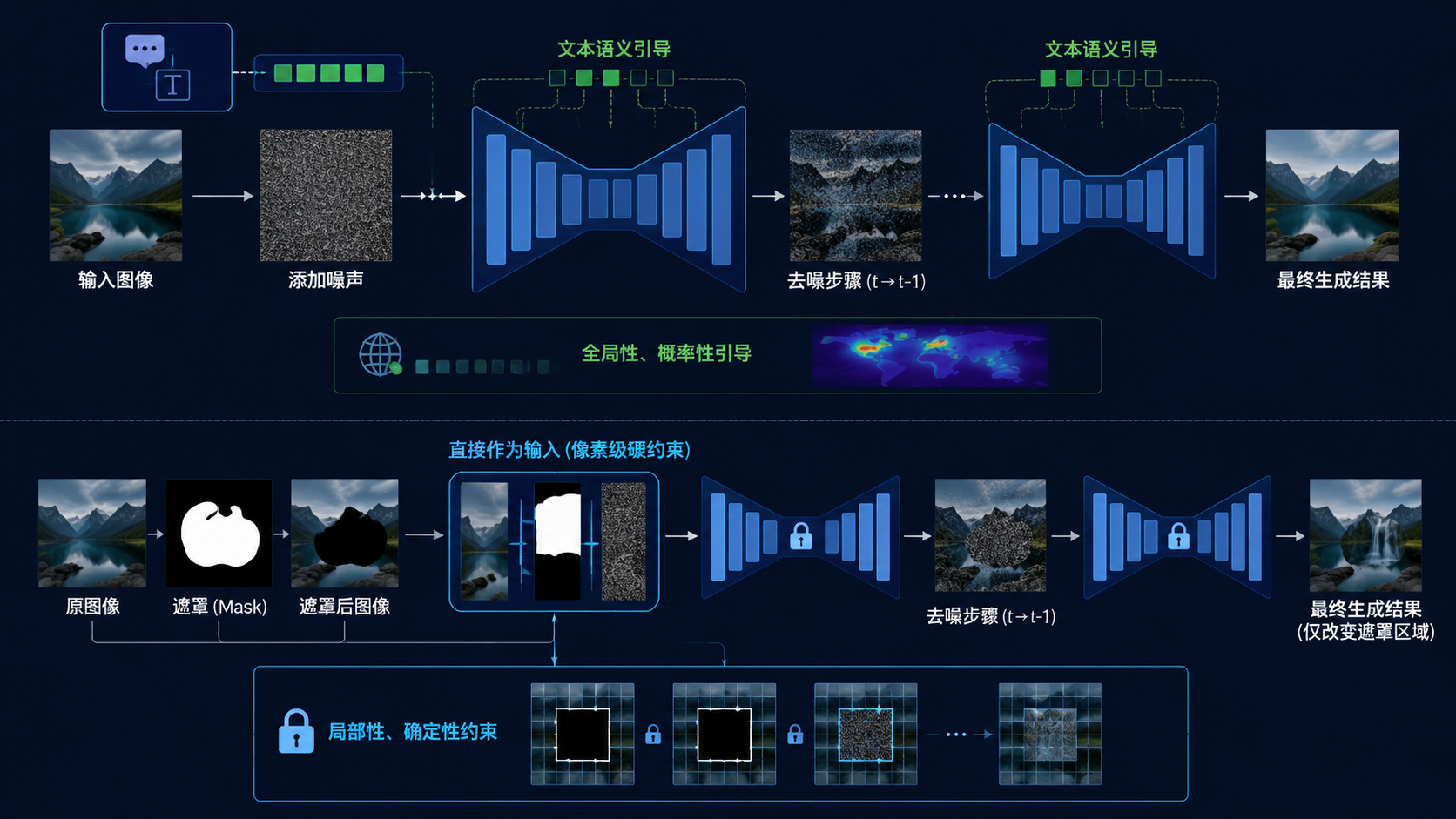
用一个比方来说:文本提示词像是给AI打了一个电话下指令,而视觉标注像是直接在AI的工作台上用红笔圈出了操作区域。后者的确定性远大于前者。[/rihide]
核心结论:把”在哪里改”交给视觉标注,把”改成什么”交给文字——各司其职,才是AI局部重绘的正确打开方式。
第三部分:工具实战——主流AI改图工具的精准操作SOP
原理讲清楚了,接下来我们进入实操环节。我会对主流AI工具献丑AI使用拆解,每个工具给出完整的操作步骤、全新的中文案例以及关键注意事项。
3.1 献丑AI:重绘工具的简单使用
工具定位:在献丑AI无限画布上,你可以结合涂抹标注实现精准局部修改。支持最高4K分辨率输出,在文字渲染、多图融合、品牌一致性方面达到行业领先水平。
📝 完整操作SOP:电商场景——将产品图中的马克杯替换为香薰蜡烛
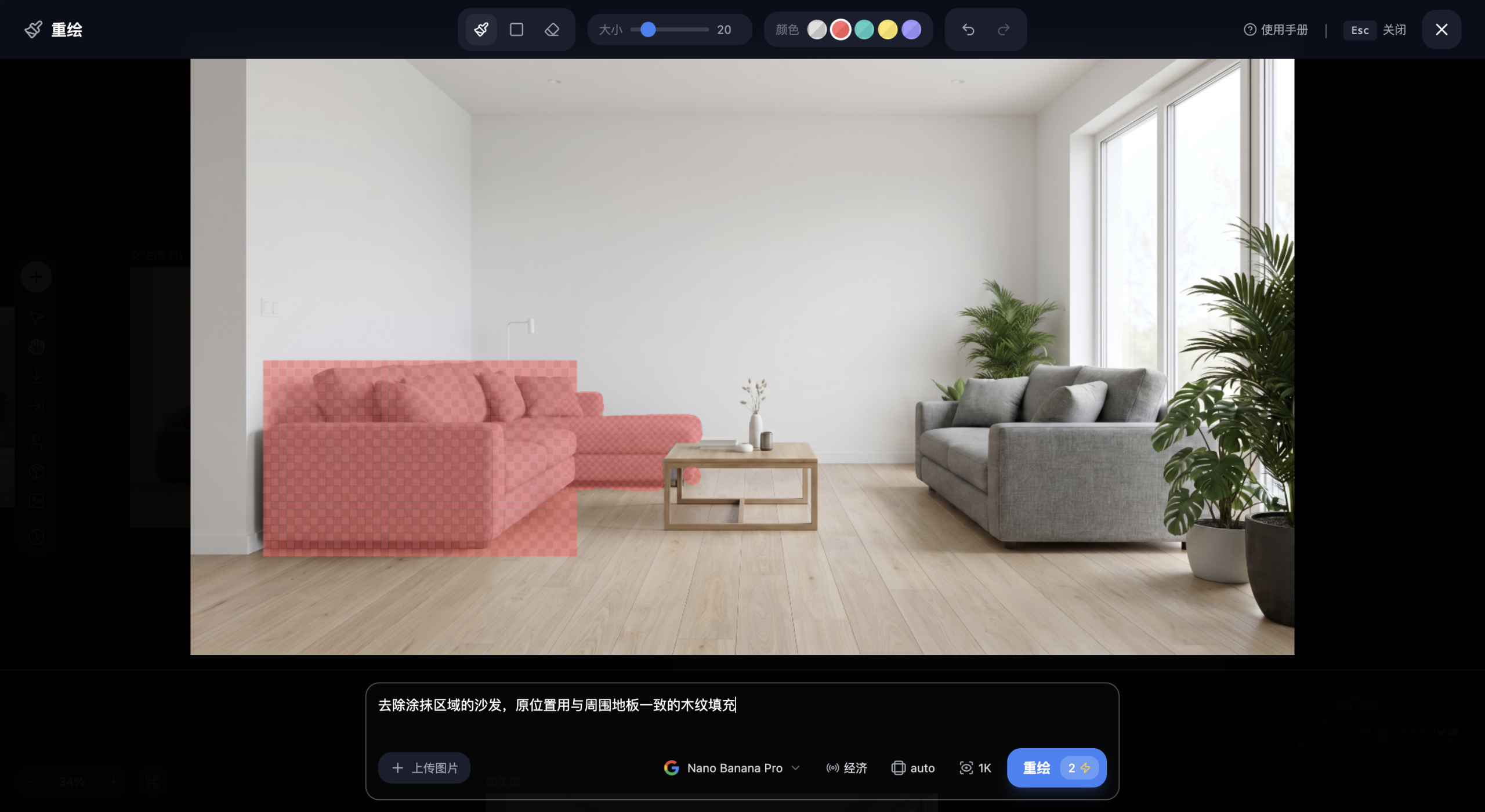
1. 上传底图 在献丑AI,上传需要编辑的电商产品场景图。本例中,图片是一张大理石桌面上摆放着一只白色马克杯、一本摊开的书、一盏台灯的生活方式场景图。[rihide]

2. 标注目标区域 在献丑AI图片节点中,使用涂抹工具将马克杯的区域标记出来。涂抹时沿着杯体的外轮廓走,确保完整覆盖杯体但不要过多地覆盖到周围桌面。
3. 输入精简指令 文本提示框中不要再写任何方位描述,直接写目标内容:
将标记区域替换为一只点燃的圆柱形白色香薰蜡烛,蜡烛高度与原杯子相近,烛焰微微摇曳
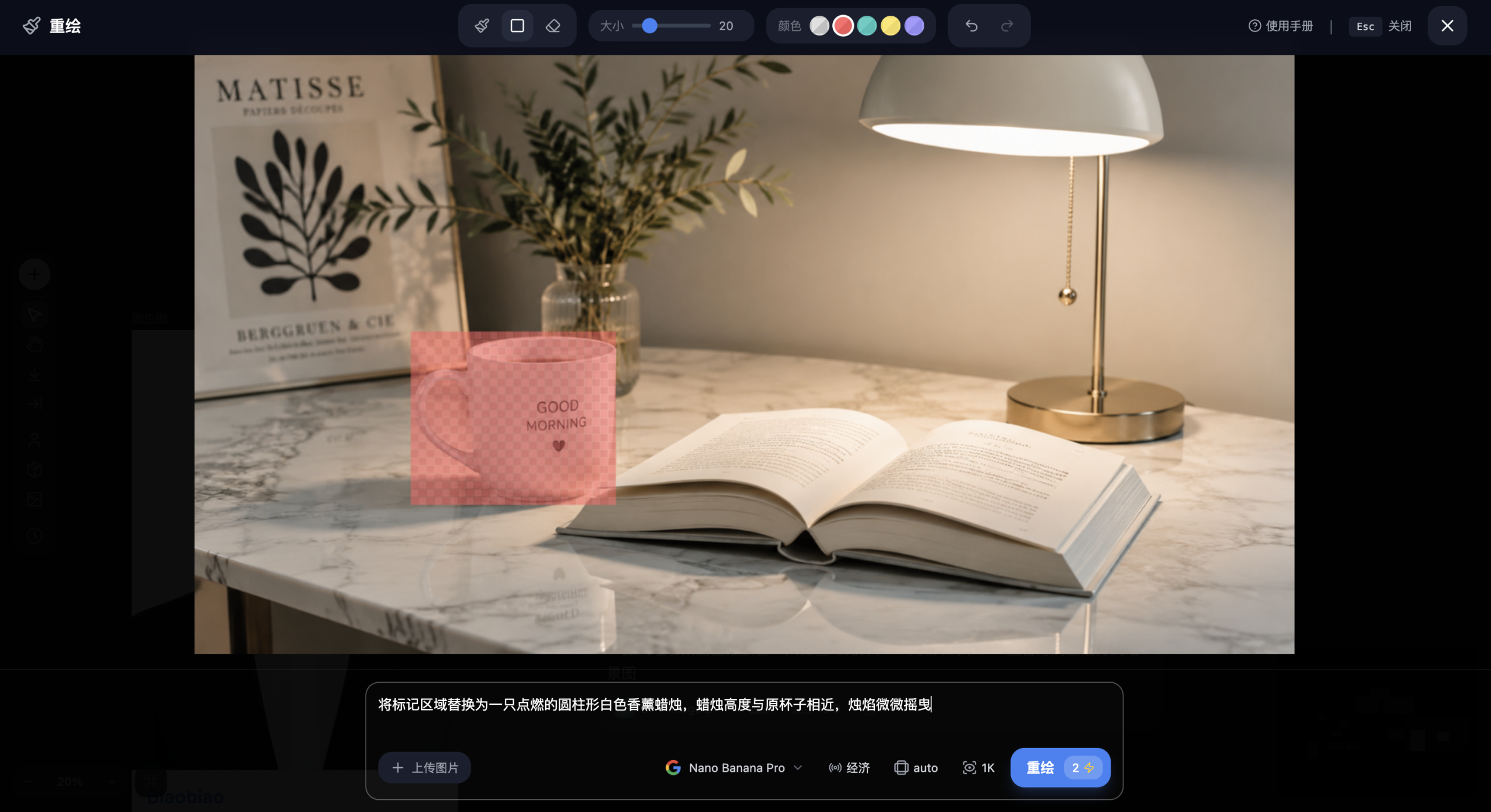
4. 生成并预览 点击生成后,Nano Banana Pro会精确地在涂抹区域内进行像素重组,自动匹配周围的大理石桌面光影和暖色调灯光环境。

5. 对话式迭代(可选) 如果蜡烛的大小或火焰效果不满意,无需重新上传,直接在对话框中追加指令:
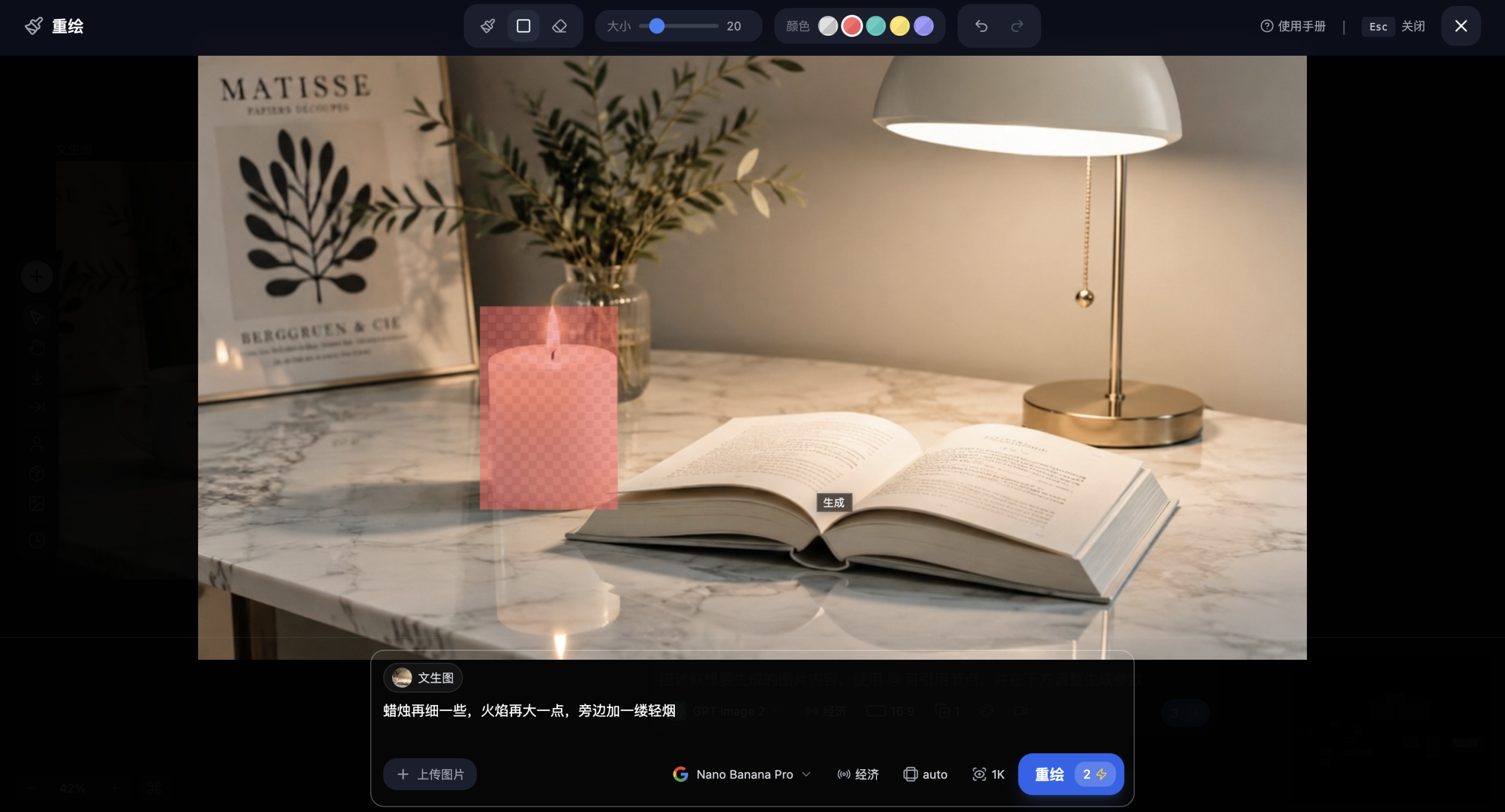
蜡烛再细一些,火焰再大一点,旁边加一缕轻烟

普通提示词 vs 结合视觉标注的提示词对比
| ❌ 纯文本方式 | ✅ 视觉标注 + 精简文本 | |
|---|---|---|
| 提示词内容 | “把桌面上靠左边台灯旁边的白色马克杯替换为一只白色香薰蜡烛,蜡烛要和杯子一样高,点着火苗” | 涂抹马克杯区域 + “一只点燃的白色圆柱形香薰蜡烛” |
| AI行为 | 可能误改台灯或书本;”靠左边台灯旁边”存在歧义 | 100%锁定涂抹区域,台灯和书本完全不受影响 |
| 平均成功率 | 約30%(需多次重试) | 90%以上 |
⚠️ 注意:先完成大改,再做细调,避免累积误差。[/rihide]
3.2 Midjourney 区域变化(Vary Region):艺术感最强的局部重绘
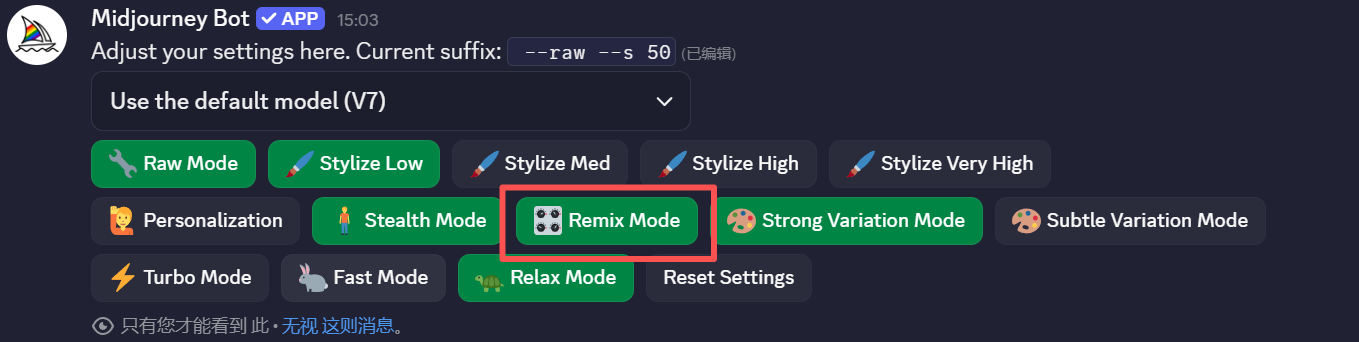
工具定位:Midjourney是当前艺术表现力最强的AI图像生成平台之一。截至2026年5月,V7为生产环境默认模型,V8/V8.1 Alpha在alpha.midjourney.com上以预览形式开放。其局部重绘功能名为区域变化(Vary Region),结合混搭模式(Remix Mode)可以在重绘特定区域的同时修改提示词,实现精准的内容替换。[rihide]
适用场景:插画创作细节调整、概念艺术迭代、高审美要求的局部修改
📝 完整操作SOP:插画场景——将画面中的猫咪替换为女孩
1. 启用 Remix 模式(必须完成)
可以在 Discord 通过以下方法:
-
在对话框中输入
/settings回车,在设置面板里点击 Remix mode 开启。 -
或者直接输入命令
/prefer remix回车。
2. 开启创作模式 在对话框中输入“ / ” ,就会自动弹出多个选项,我们选择“/image”然后按回车键,输入我们需要创作的图片提示词。

3. *放大目标图片* 点击自己满意的图下方的 U1/U2/U3/U4 按钮,把它放大成单张大图。
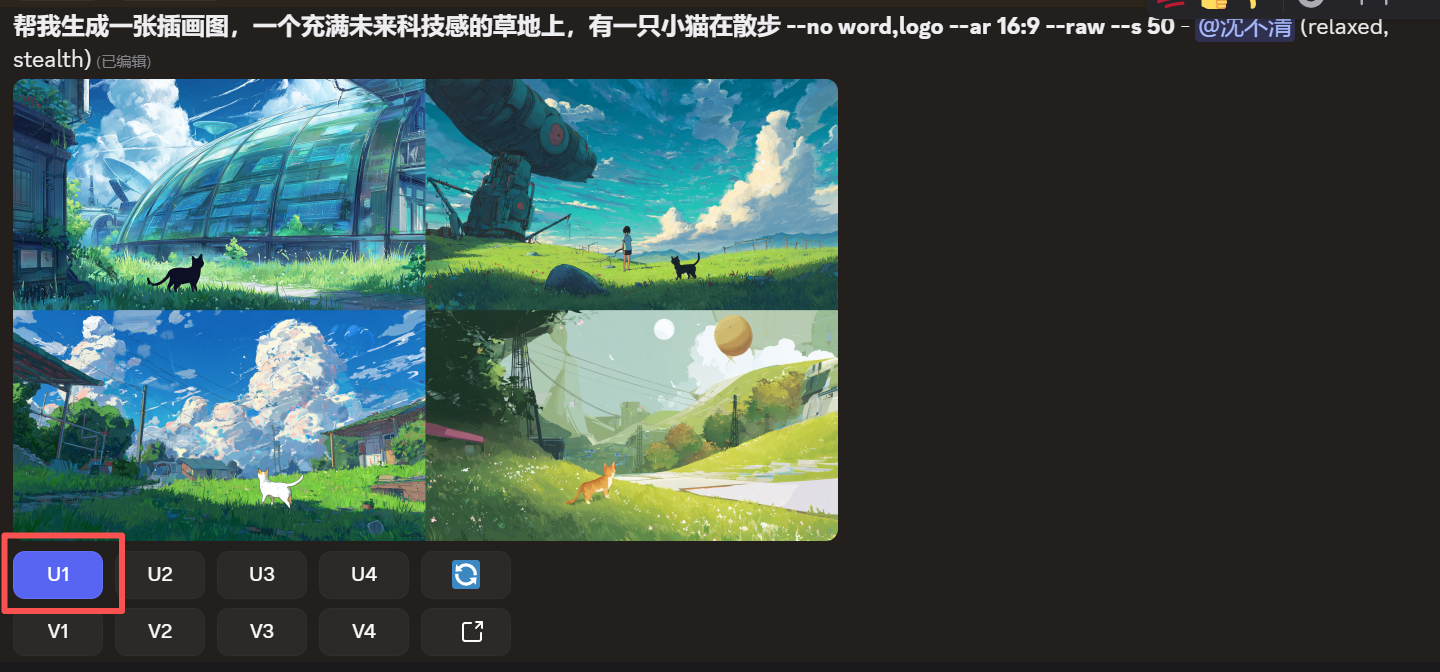
4. *点击 Vary (Region)* 在放大后的单张图下方,点击 🖌️ Vary (Region) 按钮。
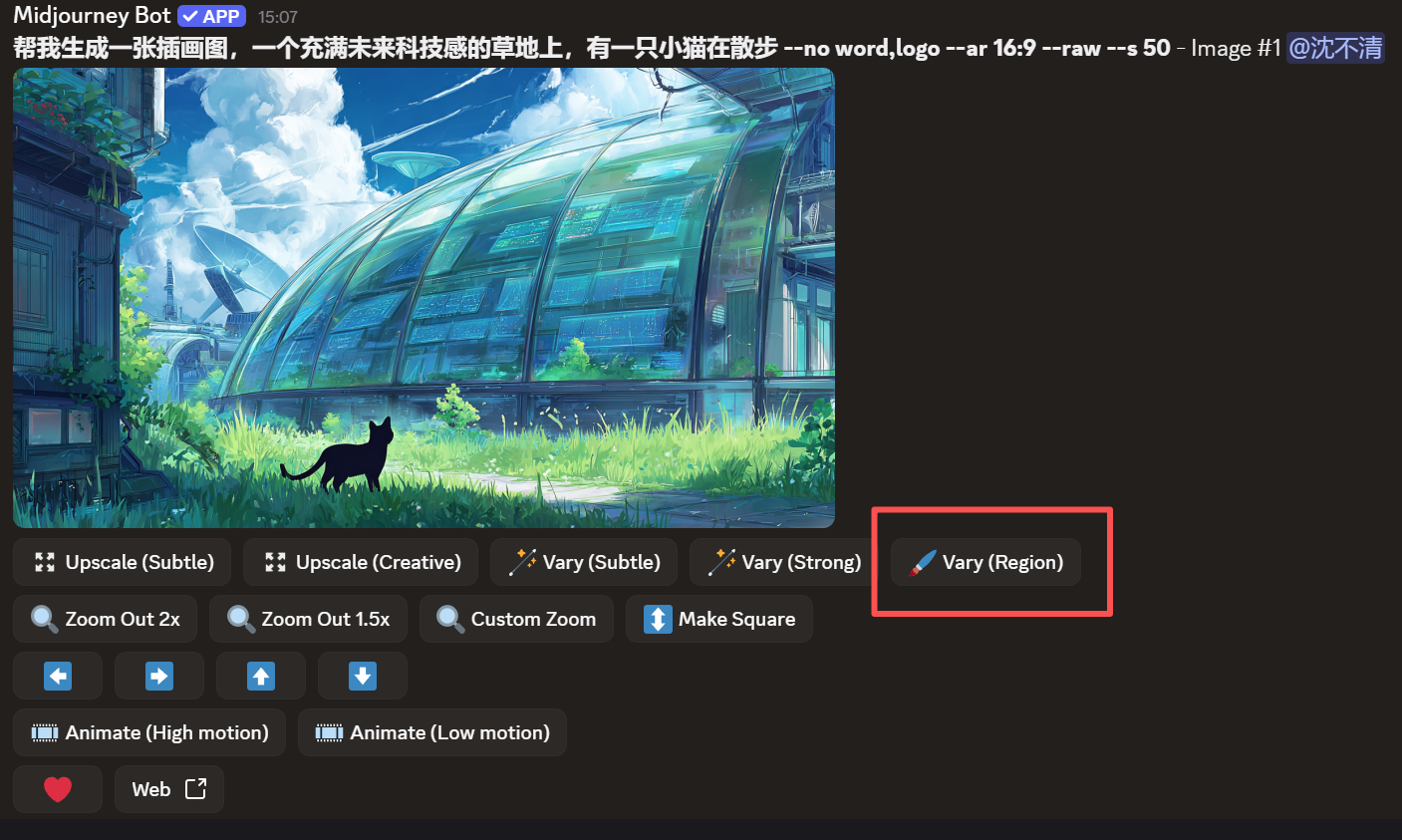
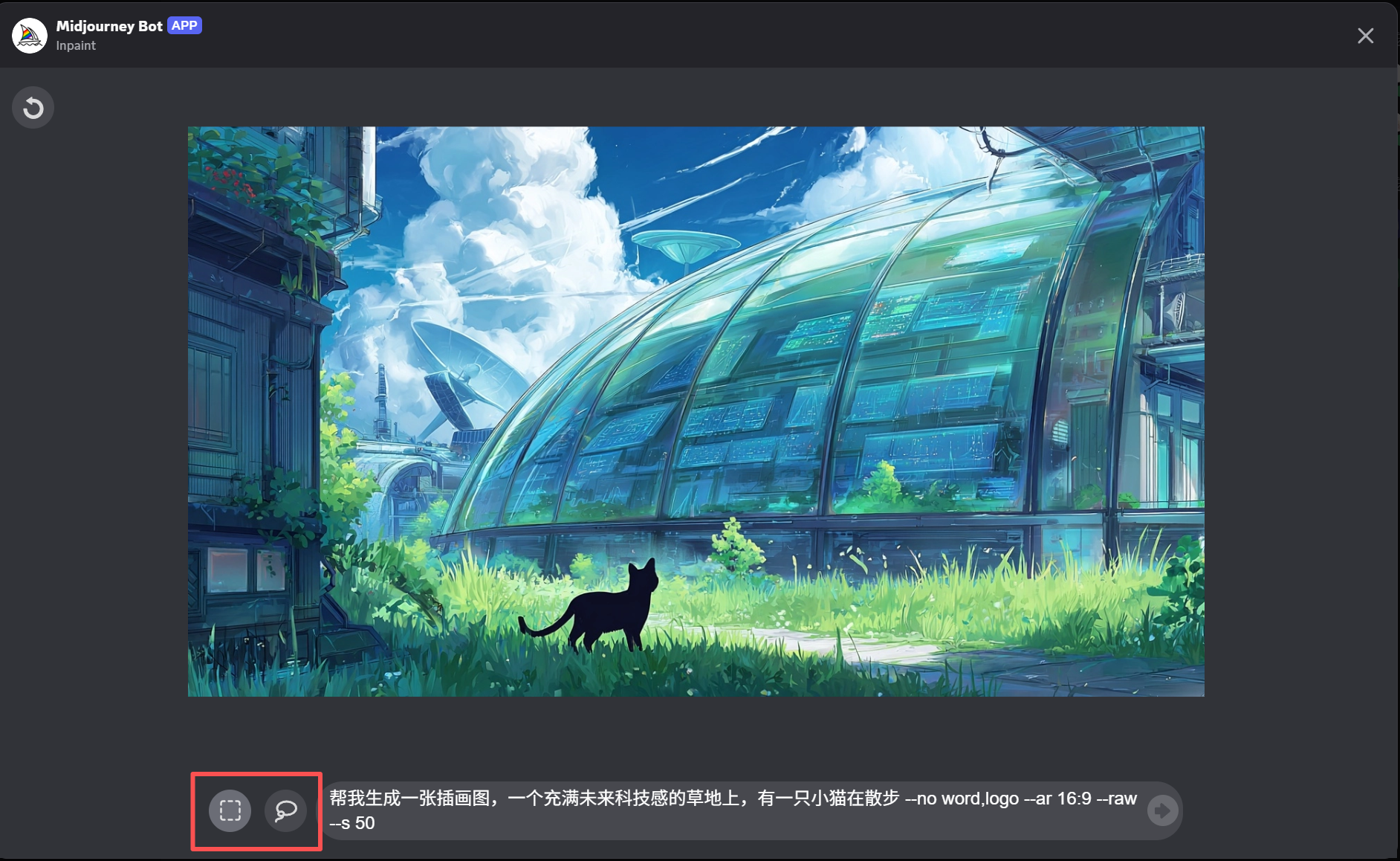
5. *进入选区界面* 会弹出编辑窗口,底部有两个工具:
-
矩形选区:框选不想要的物品区域
-
套索选区:手动画出物品的轮廓
关键点:选区要比物品本身大一整圈,给 AI 留出足够空间来重新构图,效果才自然。
6. ***修改提示词***
在输入框里,把原来那个不想要的物品描述删掉,改为你想要的新物品描述。
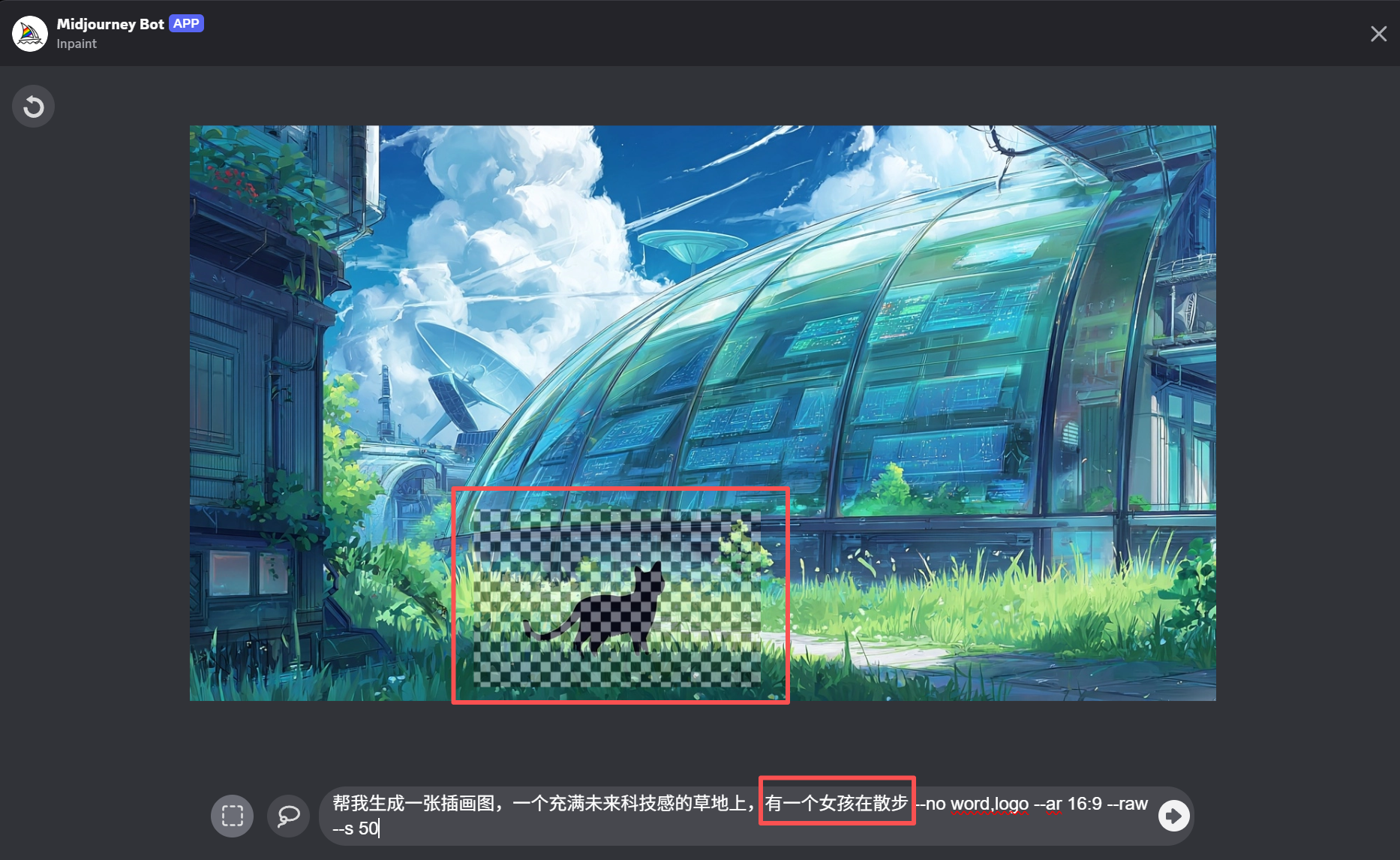
关键技巧:提示词策略
💡 Tips:Midjourney的区域变化功能中,提示词应该聚焦于选区内你想要的内容,而不是描述整张图。Midjourney会自动参考选区外的原图内容来保持画面一致性。因此,越短、越直接的提示词,效果往往越好。直接写”女孩”即可。[/rihide]
⚠️ 注意:
涂抹面积建议控制在画面的20%-50%之间。涂抹过少(低于10%),AI可能只做微小纹理变化;涂抹过多(超过60%),可能导致画面整体风格偏移。
截至2026年5月,V8 Alpha的图片可以在编辑器中使用,但编辑器的实际渲染引擎暂时使用V6.1。如果你需要V8风格的局部重绘,建议等待Midjourney官方更新V8 Edit模型。
如果需要修改多个区域,一次只改一处,分多轮进行。每次确认满意后再放大、进入下一轮区域变化。
3.4 三款工具横向对比速查表
| 对比维度 | 献丑AI | Midjourney (Vary Region) | 即梦AI (智能画布) |
|---|---|---|---|
| 最佳适用场景 | 电商/营销物料、多轮对话式迭代 | 概念艺术、插画、高审美创作 | 中文海报/社交图片、新手入门 |
| 中文指令支持 | ⭐⭐⭐⭐(通过Gemini多语言能力) | ⭐⭐(支持但英文效果更佳) | ⭐⭐⭐⭐⭐(原生中文优化) |
| 操作门槛 | 中等(需理解对话式编辑逻辑) | 中高(需熟悉Upscale→Vary Region流程) | 低(所见即所得,傻瓜式操作) |
| 艺术表现力 | ⭐⭐⭐⭐(偏真实风格) | ⭐⭐⭐⭐⭐(风格化/艺术感最强) | ⭐⭐⭐(本土审美适配好) |
| 精准控制力 | ⭐⭐⭐⭐⭐(像素级控制+对话迭代) | ⭐⭐⭐⭐(选区精度高,需配合Remix) | ⭐⭐⭐⭐(重绘强度可调,参数丰富) |
| 最大输出分辨率 | 4K | 2K(V8.1 Alpha默认HD) | 取决于原图分辨率 |
| 费用门槛 | 免费100积分,相当于50张 banana pro | $10-$120/月 | 基础功能免费,高级功能需会员 |
第四部分:进阶技法——物体位移与跨区域空间重构
掌握了基础的”原地替换”之后,我们来挑战一个更高级的任务:不只是把物体换成别的东西,而是把物体从画面的一个位置搬到另一个位置。[rihide]
4.1 什么是”空间重构”?它和”替换”有什么不同?
替换:找到元素A → 用元素B覆盖它 → A的位置不变,只是内容变了。
空间重构(Spatial Reconstruction):找到元素A → 把它从位置①移动到位置② → A的内容保持不变,但位置变了,同时位置①需要被合理地”填回去”。
空间重构比替换复杂得多,因为它涉及三个子任务:
-
擦除:把原位置的物体干净地除去,并自然填充背景
-
移植:在新位置生成该物体
-
适配:物体在新位置的透视、光影、尺寸需要自动调整以匹配新的空间关系
4.2 标记点 + 指令的联合操控法
在支持多点标注的工具中(如Nano Banana Pro),你可以用编号标记点来实现空间重构。
现代客厅室内设计,平视视角,一张灰色布艺沙发放置在客厅左侧墙边,右侧有一面大窗户,自然光透过窗户照射进来,整个房间铺设浅色橡木木纹地板,白色墙壁,中央有一张茶几,简约风格装饰,窗户旁边区域空旷有足够放置沙发的空间,窗边有绿植点缀,柔和自然光线,室内设计摄影风格,高分辨率,写实风格
📝 完整操作SOP:室内设计场景——将沙发从客厅左侧移动到窗边
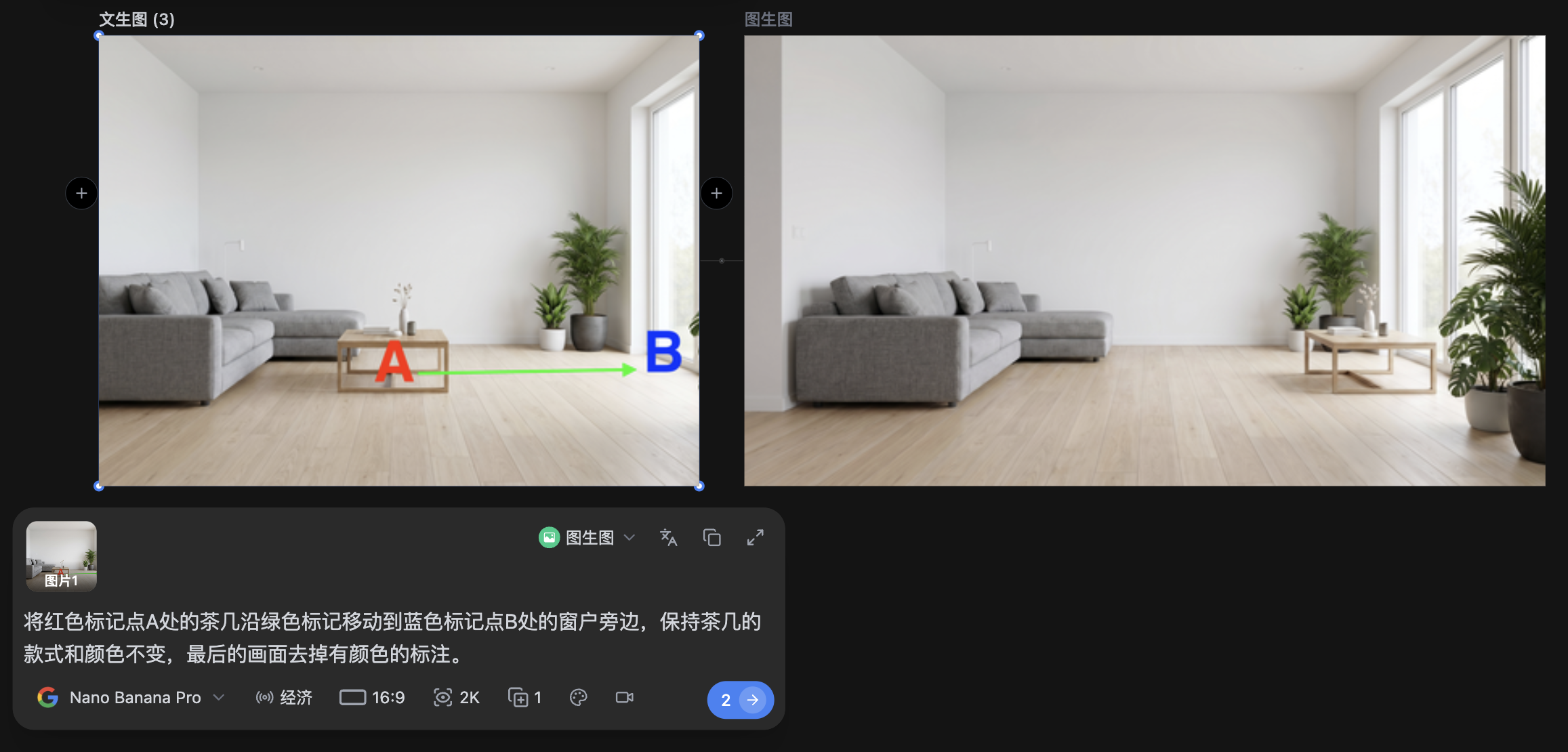
1. 在底图上标注两个位置 在图片中标注两个编号标记点:
-
标记点①:沙发当前所在位置(客厅左侧)
-
标记点②:你希望沙发移动到的位置(窗户旁边)

2. 输入位移指令
将红色标记点A处的灰色布艺沙发移动到蓝色标记点B处的窗户旁边,保持沙发的款式和颜色不变,原位置用与周围地板一致的木纹填充
此时你大概率会看到下面这样的效果:

这就是接下来要说的移动距离较大所产生的影响,但是遇到这种情况有解嘛? 我们可以分步解决,将多余部分再利用之前文章说的重绘功能去除

当然,如果移动距离短一些可以不用分步,只要标记清晰可以一步就完成
3. 生成并检查 AI会在新位置生成沙发,并自动适配窗边的自然光照射角度和阴影方向。同时,原位置会被合理填充。
💡 Tips:移动距离与分步执行的关系
如果移动距离较短(如从画面左侧移到中部),一般一次生成即可完成。
如果移动距离较大(如从画面最左移到最右),建议分两步执行:第一步先擦除原位置的物体并填充背景,第二步在新位置使用局部重绘生成物体。这样做的原因是:一次性大范围修改涉及的新生成像素过多,AI的注意力可能分散,导致新位置的物体质量下降或与背景融合不自然。
4.3 为什么AI能自动适配新位置的透视和光影?
这里涉及一个容易被忽略的底层能力:扩散模型在训练过程中,已经学到了大量关于真实世界光照规律、透视收缩和物体间空间关系的隐式知识。
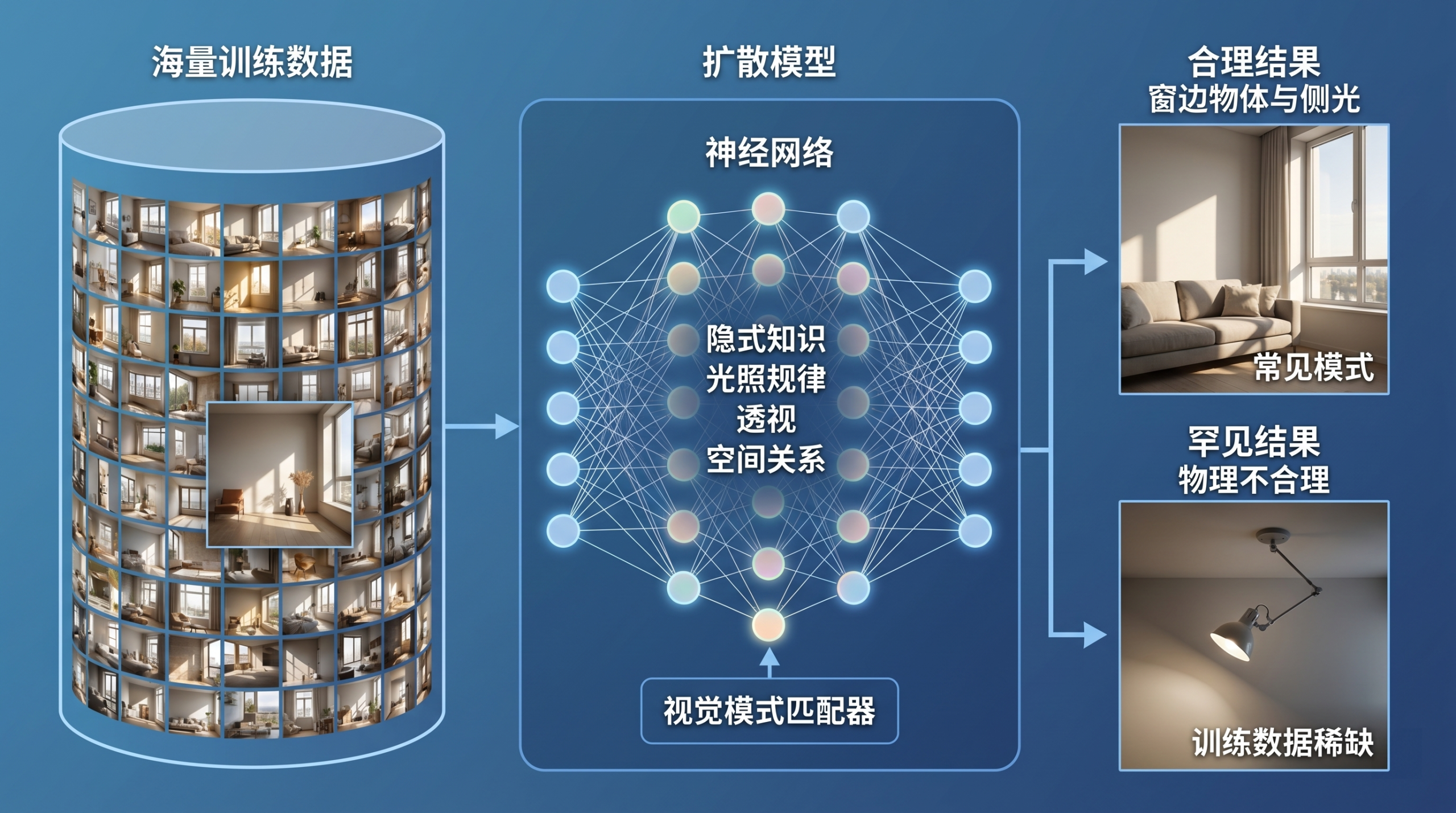
当你把沙发移动到窗边时,模型”知道”窗边会有更强的侧光——这不是因为它理解了物理原理,而是因为在它训练过的海量图片中,“窗边的物体”和”侧向自然光”总是成对出现的。扩散模型本质上是一个超大规模的视觉模式匹配器,它会自动调用这些学到的视觉规律来让结果看起来合理。
当然,这种适配有其极限——如果你要求的场景在训练数据中极其罕见(比如”把台灯移到天花板上”),AI可能无法给出物理上合理的结果。此时就需要人工介入,分步骤引导生成。[/rihide]
第五部分:避坑手册——视觉标注中最容易犯的三个致命错误
方法论再正确,实操中如果踩了关键的坑,效果依然会大打折扣。以下三个错误是我在教学中看到的最高频”翻车现场”。[rihide]
5.1 错误一:涂抹时遮盖了物体的关键特征
什么是关键特征?
每一个视觉物体都有其”最具辨识度”的视觉信息,我把它们分为三类:
-
轮廓边缘:物体与背景交界的那条线
-
骨架结构:决定物体整体形态的主要线条(如人的四肢、建筑的框架)
-
视觉重心:物体中最核心的视觉信息(如人脸、招牌上的文字、画面的主要图案)
错误示范:你想在局部重绘中移动一幅挂画,但在标注时,用不透明的涂抹把整幅画的内容都盖住了。这时AI看到的就是一个”黑洞”——它完全不知道原来这里有什么,只好凭空”猜测”,结果自然不可控。
现代客厅内部,平视视角,浅灰色墙壁左侧挂着一幅带框的抽象画,画作下方是一张米色皮质沙发,右侧是一段留白的白色墙面,适合悬挂艺术品,温暖的氛围照明,木地板,极简装饰,室内设计摄影,高分辨率,写实风格

正确做法:
| ❌ 错误涂抹 | ✅ 正确涂抹 | |
|---|---|---|
| 涂抹方式 | 把整个物体内部填满,完全遮盖 | 沿物体外轮廓涂抹,保留物体的核心内容 |
| AI看到的 | 一块空白区域,无任何参考信息 | 物体的主要形态和特征依然可见 |
| 生成结果 | AI随意”脑补”,结果不可控 | AI精确理解物体并执行指令 |
⚠️ 核心原则:涂抹标注的作用是”告诉AI这里需要处理”,而不是”把原始信息完全抹掉”。贴合边缘涂抹,保留核心内容——这12个字是视觉标注的黄金法则。

将红色标号1处的挂画改到绿色标号2处,不要更改画的形状

[ri-accordions title=”十条错误示范”]
错误示范1:标注区域过大,覆盖过多上下文
场景: 想移动餐桌上的一个花瓶到窗台上
错误做法: 标注区域把整个餐桌、椅子、周围装饰全部框选进去
后果: AI误以为你要重新生成整个餐厅区域,结果桌子款式变了、椅子消失了、整体风格走样
错误示范2:标注区域过小,只框了物体的一部分
场景: 想把一张单人椅从角落移到书桌旁
错误做法: 只框选了椅子的上半部分,椅腿和阴影没有包含在内
后果: AI只”移走”了半把椅子,原位置残留了椅腿轮廓,目标位置生成了一把比例失调的椅子
错误示范3:两个标记点距离太近,AI分不清
场景: 想把茶几从沙发正前方移到沙发侧面
错误做法: ①和②标记点几乎紧挨着,而且都在沙发附近
后果: AI无法明确区分”起点”和”终点”,生成结果中出现两个茶几,或者茶几位置几乎没变
错误示范4:只说”移动”,不描述物体特征
场景: 客厅有两把类似的椅子,你想移动其中靠门的那把
错误做法: 指令写”把椅子移到窗边”
后果: AI不知道你指的是哪把椅子,可能移错对象,或者把两把椅子合并成一把
错误示范5:没有说明原位置如何填补
场景: 把一个落地灯从墙角移到沙发旁
错误做法: 只说”把落地灯移到沙发旁边”,没有说原位置怎么处理
后果: 原位置出现诡异的”残影”——半截灯杆、模糊的轮廓,或者突然出现一个AI臆想出来的新物件填补空白
错误示范6:指令中加入了矛盾信息
场景: 想保持沙发原样移动到新位置
错误做法: 写”把灰色布艺沙发移到窗边,换成更明亮的风格”
后果: AI接收到”保持不变”和”换风格”的矛盾信号,生成结果可能是一个颜色、材质都变了的沙发,完全不是你要的
错误示范7:一次性移动多个物体,没有分步骤
场景: 想重新布置整个客厅——沙发移到窗边、茶几移到中间、电视柜换个墙面
错误做法: 一条指令里写完所有移动要求
后果: AI处理能力溢出,优先级混乱。结果可能是沙发到位了但茶几消失了,电视柜变成了书架,整体空间透视关系崩塌
错误示范8:没有考虑透视关系
场景: 把前景的一把椅子移到房间深处
错误做法: 要求”保持椅子大小不变”地移到远处
后果: 椅子出现在远处但尺寸和前景一样大,整个画面透视完全失真,看起来像椅子巨大化了
错误示范9:在复杂纹理区域做粗暴擦除
场景: 想把地毯上的一个坐垫移走
错误做法: 直接用纯色(白色/黑色)涂抹坐垫区域,然后要求AI补全
后果: AI无法准确还原坐垫下方的地毯花纹,生成区域和周围地毯图案明显断裂、不连续,像是打了一块”补丁”
错误示范10:忽略光源方向变化
场景: 把台灯从房间东侧移到西侧
错误做法: 只要求移动台灯,不提及阴影和光照变化
后果: 台灯到了新位置,但阴影方向还是朝原来的方向投射,或者原位置的光晕效果还残留着,画面物理逻辑矛盾
错误示范11:移动物体后没考虑遮挡关系
场景: 把一盆植物从桌面移到沙发后面
错误做法: 没有说明植物应该被沙发部分遮挡
后果: 植物整体悬浮式出现在沙发后方,没有正确的前后遮挡,看起来像是P图贴上去的
总结对照表
| 错误类型 | 核心问题 | 正确做法 |
|---|---|---|
| 涂抹过度 | AI丢失原始信息 | 用半透明/轮廓标注 |
| 框选过大/过小 | 范围不精确 | 精确包裹物体+适当边距 |
| 标记点模糊 | AI混淆起止点 | 标记点清晰、间距合理 |
| 描述模糊 | AI猜错对象 | 具体描述物体特征 |
| 缺少填补说明 | 原位置穿帮 | 明确说明用什么填充 |
| 信息矛盾 | AI无所适从 | 指令逻辑自洽 |
| 一次多操作 | 超出处理能力 | 分步骤逐一执行 |
| 忽略透视 | 比例失真 | 说明远近大小变化 |
| 忽略光影 | 物理逻辑矛盾 | 补充光影调整要求 |
| 忽略遮挡 | 贴图感明显 | 说明前后层级关系 |
5.2 错误二:视觉标注已经就位,文本里还在写方位词
这是一个看似微小但极具破坏力的错误。[rihide]
场景还原:你已经用画笔把右边的杯子涂抹标注好了,但在文本提示词中仍然写”把右边的杯子换成……”。
问题在哪? 当视觉标注和文本描述中都包含空间定位信息时,两者可能产生”信号冲突”。模型收到来自两个通道的定位信息,如果它们之间存在微小偏差(比如你涂抹的区域稍微偏左了一点,但文字说的是”右边”),模型需要额外消耗注意力来”调和”这种冲突,反而降低了生成质量。
正确做法:互不越界
# ❌ 有视觉标注后仍然写: 把画面右上角的白色马克杯替换为一只陶瓷花瓶,花瓶里插着一束干花 # ✅ 正确写法(已有视觉标注的情况下): 一只浅灰色陶瓷花瓶,瓶中插着一束淡粉色干花,自然光照射
原则:视觉标注负责”在哪里”,文本只负责”是什么”——各司其职,绝不越界。(有了视觉标注,不要重复的给文本描述位置,会有影响)
5.3 错误三:一次性同时修改多个区域(提到过,当重点描述一下)
场景还原:图片中有三处需要修改——背景的一棵树要去掉、桌上的杯子要换、地上的落叶要清理。你一次性全部涂抹标注,然后一句提示词交给AI。
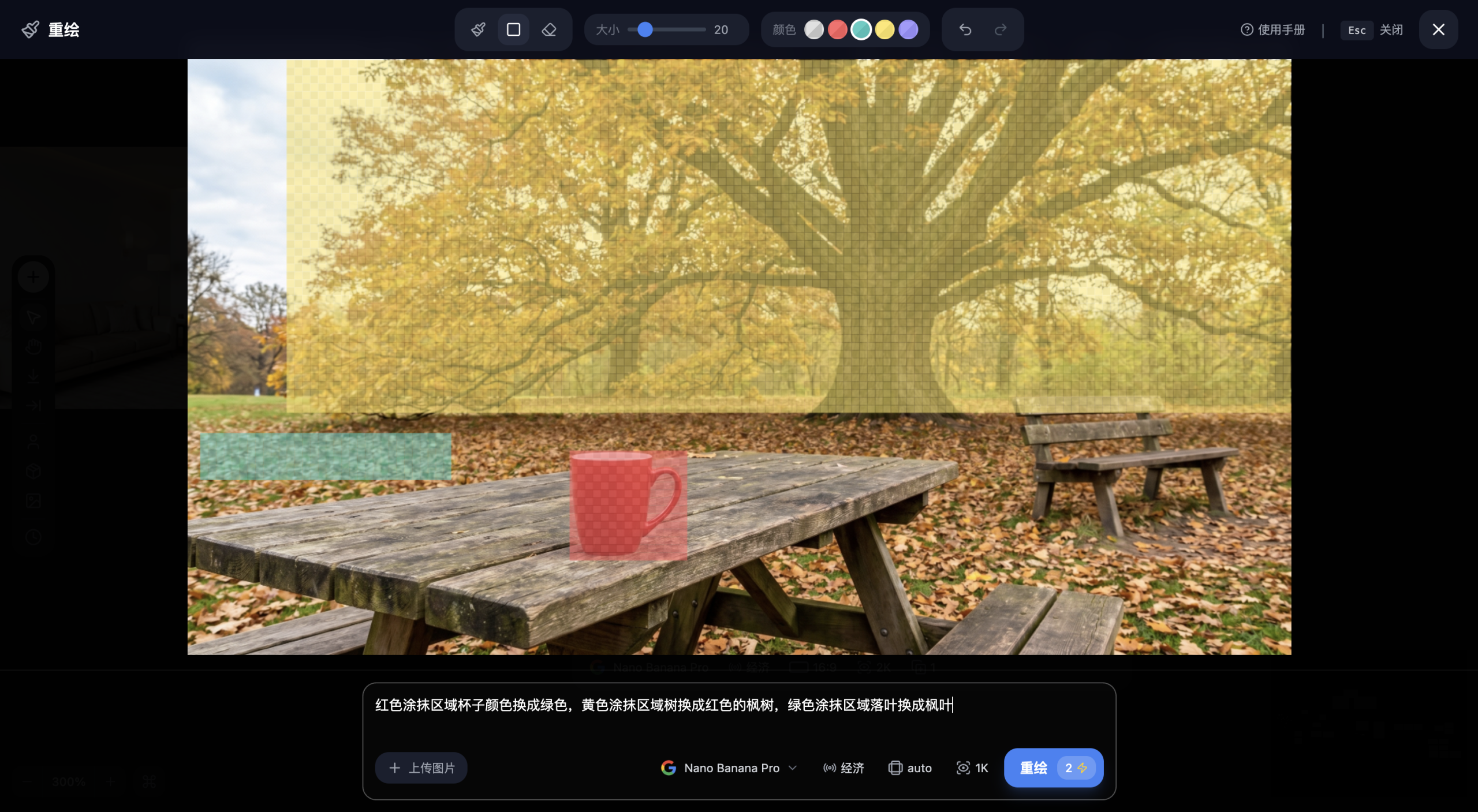
问题在哪? 扩散模型的注意力机制在处理多个不相邻的修改区域时,容易出现”注意力分散”——模型需要同时在三个不同位置进行像素级的重建和融合,计算复杂度急剧上升,每个区域分配到的”注意力资源”也相应减少。
结果往往是:
-
某个区域改得不错,但另一个区域出现明显瑕疵
-
不同区域之间的风格/光影出现不一致
-
极端情况下整张图的节奏和氛围被打乱

正确做法:一次一处,逐轮迭代
-
第一轮:只涂抹并修改背景中的树 → 确认满意 → 保存结果
-
第二轮:在上一轮的结果基础上,涂抹并修改桌上的杯子 → 确认满意 → 保存
-
第三轮:在上一轮的结果基础上,涂抹并清理地上的落叶
💡 Tips:这种”逐轮迭代”的方式虽然步骤多了一些,但总耗时反而更短——因为每一步的成功率极高(90%以上),而一次改多处的成功率可能不到30%,需要反复重试。3次×90%成功率 远优于 1次×30%成功率×多轮重试。[/rihide]
第六部分:思维升级——从”碰运气”到”工业化流程”
6.1 两种创作者心态的根本区别
学到这里,你已经掌握了视觉标注法的全部操作技巧。但比技巧更重要的,是底层思维方式的转变。
| 旧范式:”在黑暗中呼喊” | 新范式:”手握画笔的导演” | |
|---|---|---|
| 沟通方式 | 用文字穷举视觉细节,希望AI”听懂” | 用视觉标注精确定位,用文字简洁定义目标 |
| 心理状态 | 被动等待、碰运气、”这次能行吗?” | 主动掌控、有预期、”这里改成这样” |
| 失败归因 | “AI太笨了,听不懂人话” | “我的输入方式需要优化” |
| 效率曲线 | 越复杂的修改越痛苦,时间指数增长 | 复杂度提升但效率基本线性,可控可预期 |
本质差异在于:你不再试图用一种模态(文字)去描述另一种模态(视觉)的信息,而是让每种模态负责其最擅长的通信任务。
6.2 构建你的精准改图工作流
将前面所有知识点串联起来,你可以按以下流程构建属于自己的标准化精准改图工作流:
Step 1 → 审查底图 仔细检查AI生成的图片,逐区域标记出所有需要修改的位置,并为每处修改明确”目标状态”。
Step 2 → 排定优先级 如果有多处需要修改,确定执行顺序。一般原则:先改大面积区域,再改小细节;先改结构性问题,再改风格微调。
Step 3 → 选择工具 根据任务特性选择最适合的工具:
-
需要多轮改图迭代?→ 献丑AI
-
追求极致艺术表现力?→ Midjourney
-
中文场景快速处理?→ 即梦AI
Step 4 → 精确标注 遵循”贴合边缘、保留核心”的黄金法则,用涂抹/选区/标记点锁定操作区域。
Step 5 → 精简文本 只写”是什么”,不写”在哪里”。提示词越短越精准,越直接越有效。
Step 6 → 生成 → 检查 → 迭代 每次只改一处,确认满意后再进入下一处。检查重点包括:边缘融合是否自然、光影方向是否一致、色温是否和谐。
Step 7 → 质检输出 最终导出时,选择无损格式(推荐PNG),关闭自动压缩,确保分辨率与需求匹配。
总结与行动清单
📌 全文五大核心要点
-
AI听不懂精确的空间指令——纯文本描述在定位修改目标时存在天然的模糊性,画面越复杂失败率越高。
-
提示词远不止文字——底图、视觉标注和文本构成了三层权重各异的提示体系,视觉标注在空间定位上拥有碾压文本的权重优势。
-
视觉标注法的核心原则——让”在哪里改”归视觉标注,让”改成什么”归文字,各司其职、互不越界。
-
三大工具各有所长——Nano Banana Pro极致精控+对话迭代,Midjourney艺术表现力顶级,即梦AI中文友好+新手零门槛。
-
避坑比提效更重要——不遮盖关键特征、不在文本中重复方位词、每次只改一处,这三条铁律能让你少踩90%的坑。
✅ 立即可执行的三步行动清单
行动一:今天——选择你最常用的AI图像工具(以上三款任选其一),找一张需要局部修改的图片,按照本文SOP完整走一遍视觉标注+精简文本的改图流程。亲身体验”精准命中”和”反复抽卡”的差异。
行动二:本周——将你常见的改图需求分为三类(物体替换、背景调整、文字修正),为每类需求建立一个标准化的提示词模板,减少每次改图时的”从头想”成本。
行动三:持续——养成”先标注、后写词”的操作习惯。每次需要AI局部修改时,第一反应不是打字,而是拿起画笔。当这个习惯成为肌肉记忆,你的AI改图效率将产生质的飞跃。
本文所有操作步骤和工具特性信息基于2026年4月的最新版本验证。AI工具迭代迅速,如遇界面或功能差异,请以各平台官方文档为准。
发表回复